 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModality-Balanced Models for Visual Dialogue
Paper and Code
Jan 17, 2020

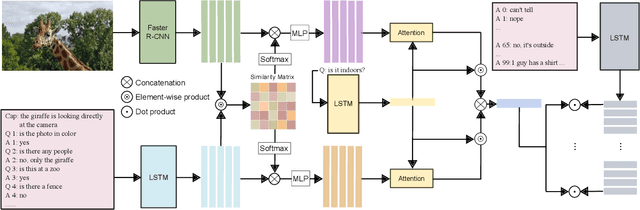
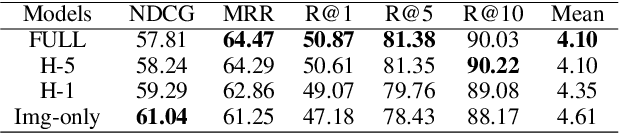
The Visual Dialog task requires a model to exploit both image and conversational context information to generate the next response to the dialogue. However, via manual analysis, we find that a large number of conversational questions can be answered by only looking at the image without any access to the context history, while others still need the conversation context to predict the correct answers. We demonstrate that due to this reason, previous joint-modality (history and image) models over-rely on and are more prone to memorizing the dialogue history (e.g., by extracting certain keywords or patterns in the context information), whereas image-only models are more generalizable (because they cannot memorize or extract keywords from history) and perform substantially better at the primary normalized discounted cumulative gain (NDCG) task metric which allows multiple correct answers. Hence, this observation encourages us to explicitly maintain two models, i.e., an image-only model and an image-history joint model, and combine their complementary abilities for a more balanced multimodal model. We present multiple methods for this integration of the two models, via ensemble and consensus dropout fusion with shared parameters. Empirically, our models achieve strong results on the Visual Dialog challenge 2019 (rank 3 on NDCG and high balance across metrics), and substantially outperform the winner of the Visual Dialog challenge 2018 on most metrics.