 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobBERT: a Dutch RoBERTa-based Language Model
Paper and Code
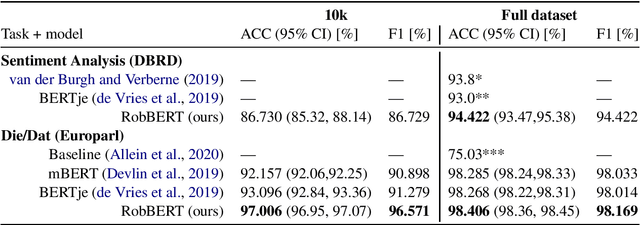

Pre-trained language models have been dominating the field of natural language processing in recent years, and have led to significant performance gains for various complex natural language tasks. One of the most prominent pre-trained language models is BERT (Bi-directional Encoders for Transformers), which was released as an English as well as a multilingual version. Although multilingual BERT performs well on many tasks, recent studies showed that BERT models trained on a single language significantly outperform the multilingual results. Training a Dutch BERT model thus has a lot of potential for a wide range of Dutch NLP tasks. While previous approaches have used earlier implementations of BERT to train their Dutch BERT, we used RoBERTa, a robustly optimized BERT approach, to train a Dutch language model called RobBERT. We show that RobBERT improves state of the art results in Dutch-specific language tasks, and also outperforms other existing Dutch BERT-based models in sentiment analysis. These results indicate that RobBERT is a powerful pre-trained model for fine-tuning for a large variety of Dutch language tasks. We publicly release this pre-trained model in hope of supporting further downstream Dutch NLP applications.