 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextual Sense Making by Fusing Scene Classification, Detections, and Events in Full Motion Video
Paper and Code
Jan 16, 2020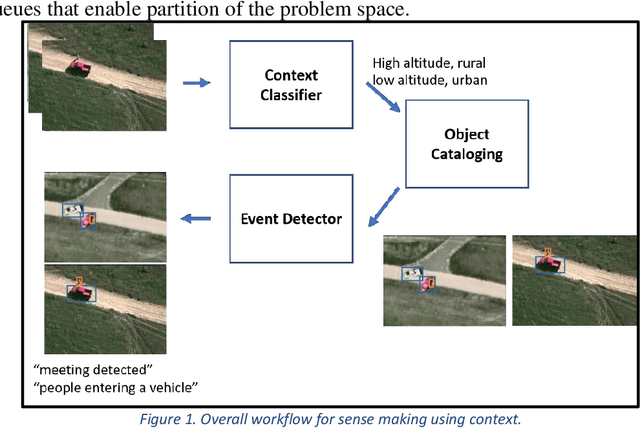
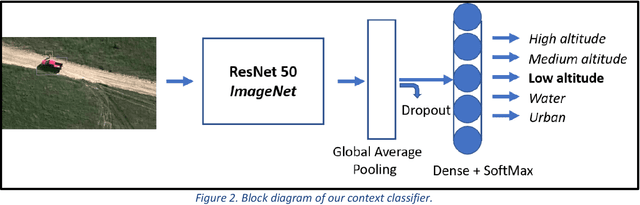
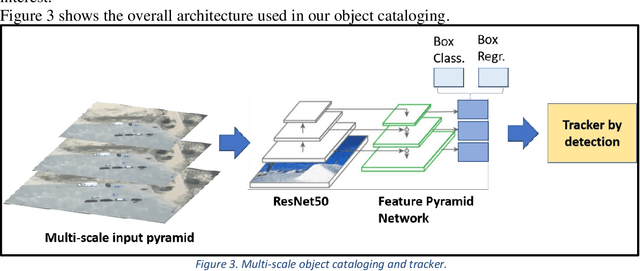

With the proliferation of imaging sensors, the volume of multi-modal imagery far exceeds the ability of human analysts to adequately consume and exploit it. Full motion video (FMV) possesses the extra challenge of containing large amounts of redundant temporal data. We aim to address the needs of human analysts to consume and exploit data given aerial FMV. We have investigated and designed a system capable of detecting events and activities of interest that deviate from the baseline patterns of observation given FMV feeds. We have divided the problem into three tasks: (1) Context awareness, (2) object cataloging, and (3) event detection. The goal of context awareness is to constraint the problem of visual search and detection in video data. A custom image classifier categorizes the scene with one or multiple labels to identify the operating context and environment. This step helps reducing the semantic search space of downstream tasks in order to increase their accuracy. The second step is object cataloging, where an ensemble of object detectors locates and labels any known objects found in the scene (people, vehicles, boats, planes, buildings, etc.). Finally, context information and detections are sent to the event detection engine to monitor for certain behaviors. A series of analytics monitor the scene by tracking object counts, and object interactions. If these object interactions are not declared to be commonly observed in the current scene, the system will report, geolocate, and log the event. Events of interest include identifying a gathering of people as a meeting and/or a crowd, alerting when there are boats on a beach unloading cargo, increased count of people entering a building, people getting in and/or out of vehicles of interest, etc. We have applied our methods on data from different sensors at different resolutions in a variety of geographical areas.