 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsumer-Driven Explanations for Machine Learning Decisions: An Empirical Study of Robustness
Paper and Code
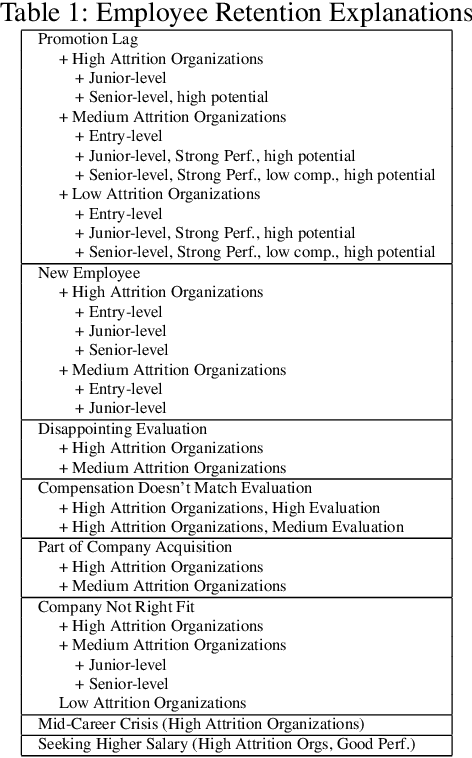

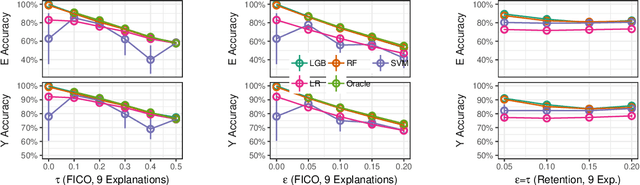

Many proposed methods for explaining machine learning predictions are in fact challenging to understand for nontechnical consumers. This paper builds upon an alternative consumer-driven approach called TED that asks for explanations to be provided in training data, along with target labels. Using semi-synthetic data from credit approval and employee retention applications, experiments are conducted to investigate some practical considerations with TED, including its performance with different classification algorithms, varying numbers of explanations, and variability in explanations. A new algorithm is proposed to handle the case where some training examples do not have explanations. Our results show that TED is robust to increasing numbers of explanations, noisy explanations, and large fractions of missing explanations, thus making advances toward its practical deployment.