Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Stopping Rule for Kernel-based Gradient Descent Algorithms
Paper and Code
Jan 09, 2020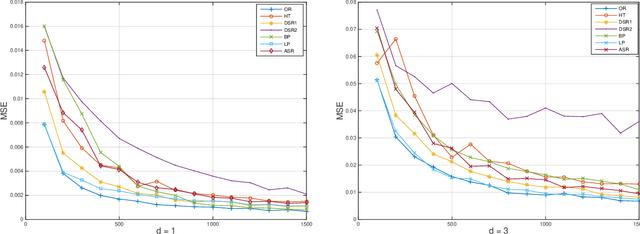
In this paper, we propose an adaptive stopping rule for kernel-based gradient descent (KGD) algorithms. We introduce the empirical effective dimension to quantify the increments of iterations in KGD and derive an implementable early stopping strategy. We analyze the performance of the adaptive stopping rule in the framework of learning theory. Using the recently developed integral operator approach, we rigorously prove the optimality of the adaptive stopping rule in terms of showing the optimal learning rates for KGD equipped with this rule. Furthermore, a sharp bound on the number of iterations in KGD equipped with the proposed early stopping rule is also given to demonstrate its computational advantage.
* 32 pages, 2 figures
View paper on