 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLTP: A New Active Learning Strategy for CRF-Based Named Entity Recognition
Paper and Code

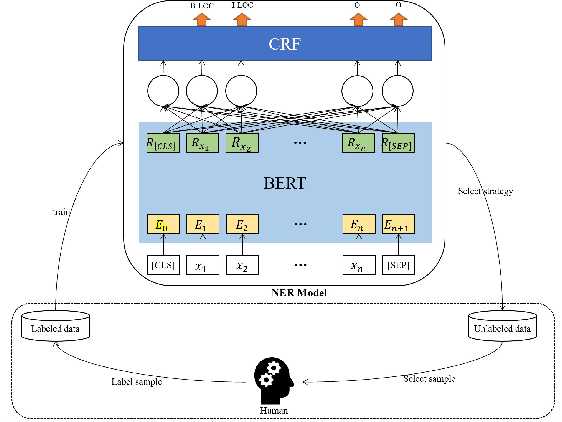
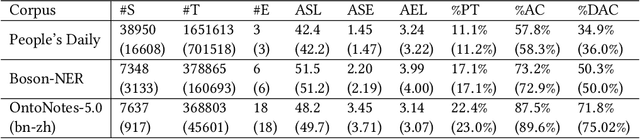
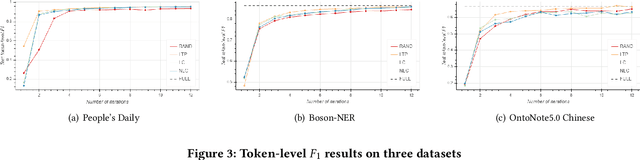
In recent years, deep learning has achieved great success in many natural language processing tasks including named entity recognition. The shortcoming is that a large amount of manually-annotated data is usually required. Previous studies have demonstrated that both transfer learning and active learning could elaborately reduce the cost of data annotation in terms of their corresponding advantages, but there is still plenty of room for improvement. We assume that the convergence of the two methods can complement with each other, so that the model could be trained more accurately with less labelled data, and active learning method could enhance transfer learning method to accurately select the minimum data samples for iterative learning. However, in real applications we found this approach is challenging because the sample selection of traditional active learning strategy merely depends on the final probability value of its model output, and this makes it quite difficult to evaluate the quality of the selected data samples. In this paper, we first examine traditional active learning strategies in a specific case of BERT-CRF that has been widely used in named entity recognition. Then we propose an uncertainty-based active learning strategy called Lowest Token Probability (LTP) which considers not only the final output but also the intermediate results. We test LTP on multiple datasets, and the experiments show that LTP performs better than traditional strategies (incluing LC and NLC) on both token-level $F_1$ and sentence-level accuracy, especially in complex imbalanced datasets.