 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting Deep Learning for Sentiment Classification of Code-Switched Informal Short Text
Paper and Code

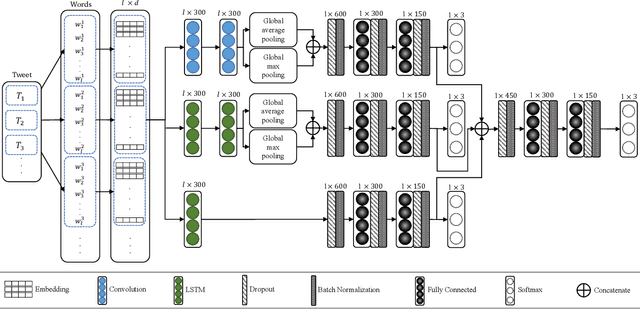
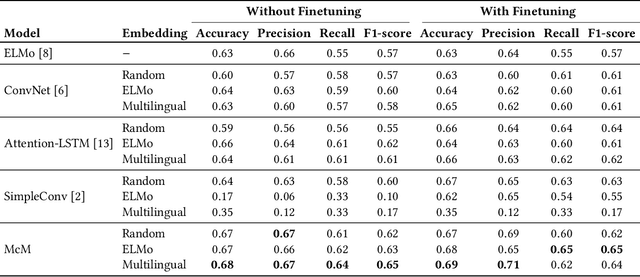
Nowadays, an abundance of short text is being generated that uses nonstandard writing styles influenced by regional languages. Such informal and code-switched content are under-resourced in terms of labeled datasets and language models even for popular tasks like sentiment classification. In this work, we (1) present a labeled dataset called MultiSenti for sentiment classification of code-switched informal short text, (2) explore the feasibility of adapting resources from a resource-rich language for an informal one, and (3) propose a deep learning-based model for sentiment classification of code-switched informal short text. We aim to achieve this without any lexical normalization, language translation, or code-switching indication. The performance of the proposed models is compared with three existing multilingual sentiment classification models. The results show that the proposed model performs better in general and adapting character-based embeddings yield equivalent performance while being computationally more efficient than training word-based domain-specific embeddings.