 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Human Judgments of Causality
Paper and Code
Dec 19, 2019

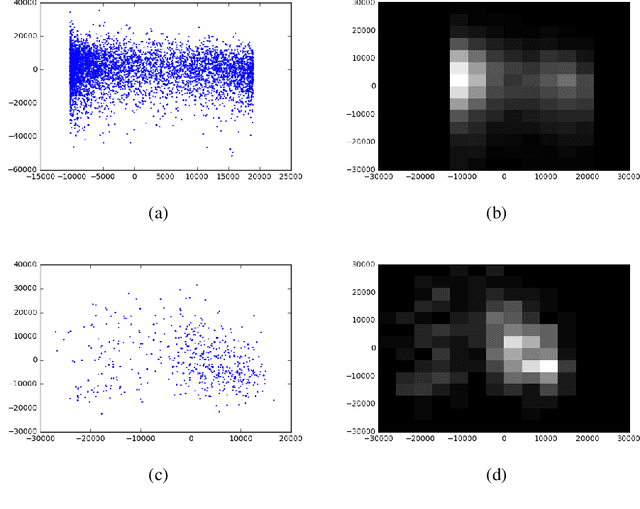
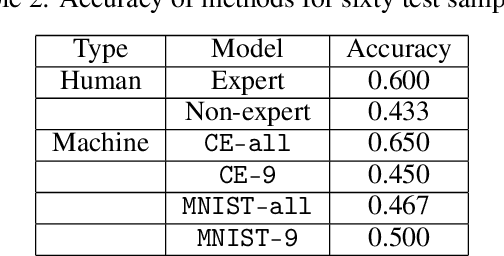
Discriminating between causality and correlation is a major problem in machine learning, and theoretical tools for determining causality are still being developed. However, people commonly make causality judgments and are often correct, even in unfamiliar domains. What are humans doing to make these judgments? This paper examines differences in human experts' and non-experts' ability to attribute causality by comparing their performances to those of machine-learning algorithms. We collected human judgments by using Amazon Mechanical Turk (MTurk) and then divided the human subjects into two groups: experts and non-experts. We also prepared expert and non-expert machine algorithms based on different training of convolutional neural network (CNN) models. The results showed that human experts' judgments were similar to those made by an "expert" CNN model trained on a large number of examples from the target domain. The human non-experts' judgments resembled the prediction outputs of the CNN model that was trained on only the small number of examples used during the MTurk instruction. We also analyzed the differences between the expert and non-expert machine algorithms based on their neural representations to evaluate the performances, providing insight into the human experts' and non-experts' cognitive abilities.