 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysing Deep Reinforcement Learning Agents Trained with Domain Randomisation
Paper and Code
Dec 18, 2019

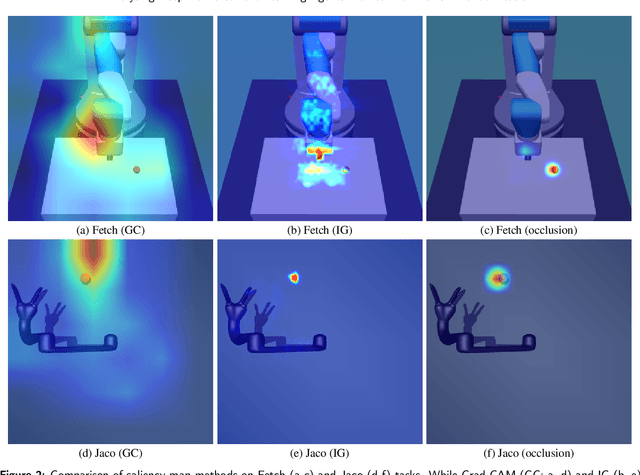
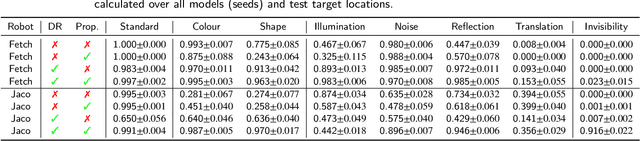
Deep reinforcement learning has the potential to train robots to perform complex tasks in the real world without requiring accurate models of the robot or its environment. A practical approach is to train agents in simulation, and then transfer them to the real world. One of the most popular methods for achieving this is to use domain randomisation, which involves randomly perturbing various aspects of a simulated environment in order to make trained agents robust to the reality gap between the simulator and the real world. However, less work has gone into understanding such agents-which are deployed in the real world-beyond task performance. In this work we examine such agents, through qualitative and quantitative comparisons between agents trained with and without visual domain randomisation, in order to provide a better understanding of how they function. In this work, we train agents for Fetch and Jaco robots on a visuomotor control task, and evaluate how well they generalise using different unit tests. We tie this with interpretability techniques, providing both quantitative and qualitative data. Finally, we investigate the internals of the trained agents by examining their weights and activations. Our results show that the primary outcome of domain randomisation is more redundant, entangled representations, accompanied with significant statistical/structural changes in the weights; moreover, the types of changes are heavily influenced by the task setup and presence of additional proprioceptive inputs. Furthermore, even with an improved saliency method introduced in this work, we show that qualitative studies may not always correspond with quantitative measures, necessitating the use of a wide suite of inspection tools in order to provide sufficient insights into the behaviour of trained agents.