 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-Term Planning and Situational Awareness in OpenAI Five
Paper and Code
Dec 13, 2019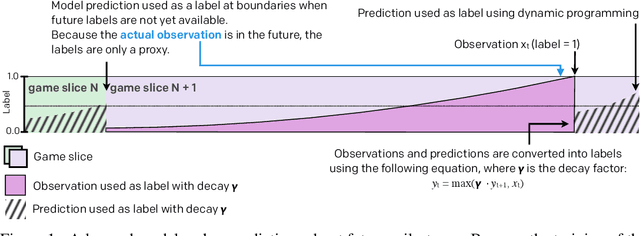
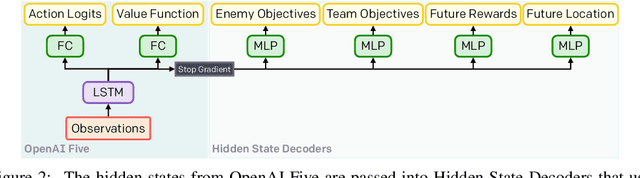
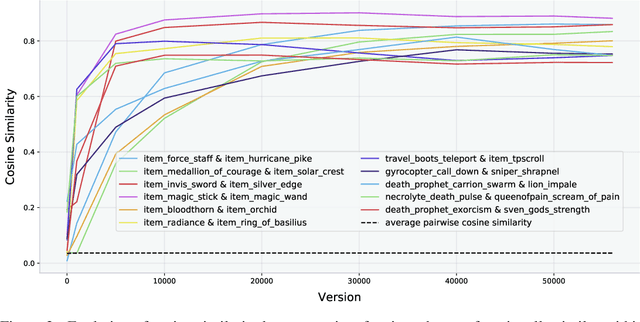
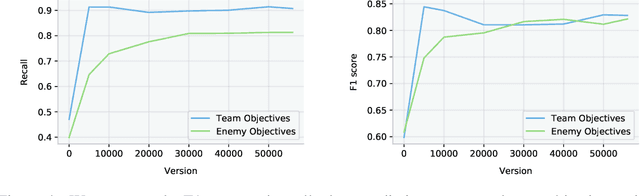
Understanding how knowledge about the world is represented within model-free deep reinforcement learning methods is a major challenge given the black box nature of its learning process within high-dimensional observation and action spaces. AlphaStar and OpenAI Five have shown that agents can be trained without any explicit hierarchical macro-actions to reach superhuman skill in games that require taking thousands of actions before reaching the final goal. Assessing the agent's plans and game understanding becomes challenging given the lack of hierarchy or explicit representations of macro-actions in these models, coupled with the incomprehensible nature of the internal representations. In this paper, we study the distributed representations learned by OpenAI Five to investigate how game knowledge is gradually obtained over the course of training. We also introduce a general technique for learning a model from the agent's hidden states to identify the formation of plans and subgoals. We show that the agent can learn situational similarity across actions, and find evidence of planning towards accomplishing subgoals minutes before they are executed. We perform a qualitative analysis of these predictions during the games against the DotA 2 world champions OG in April 2019.