 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUCT-ADP Progressive Bias Algorithm for Solving Gomoku
Paper and Code
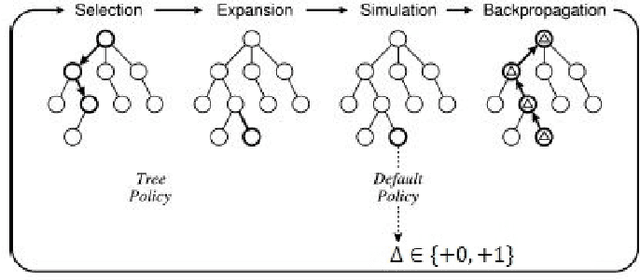
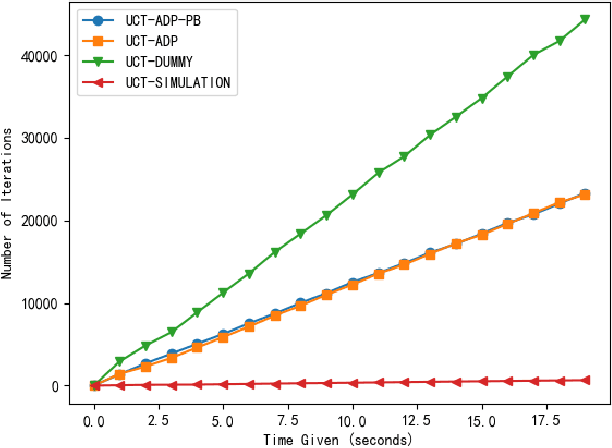
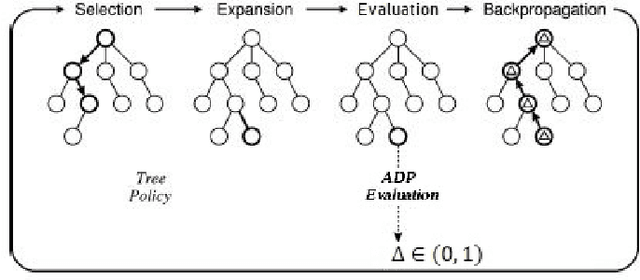
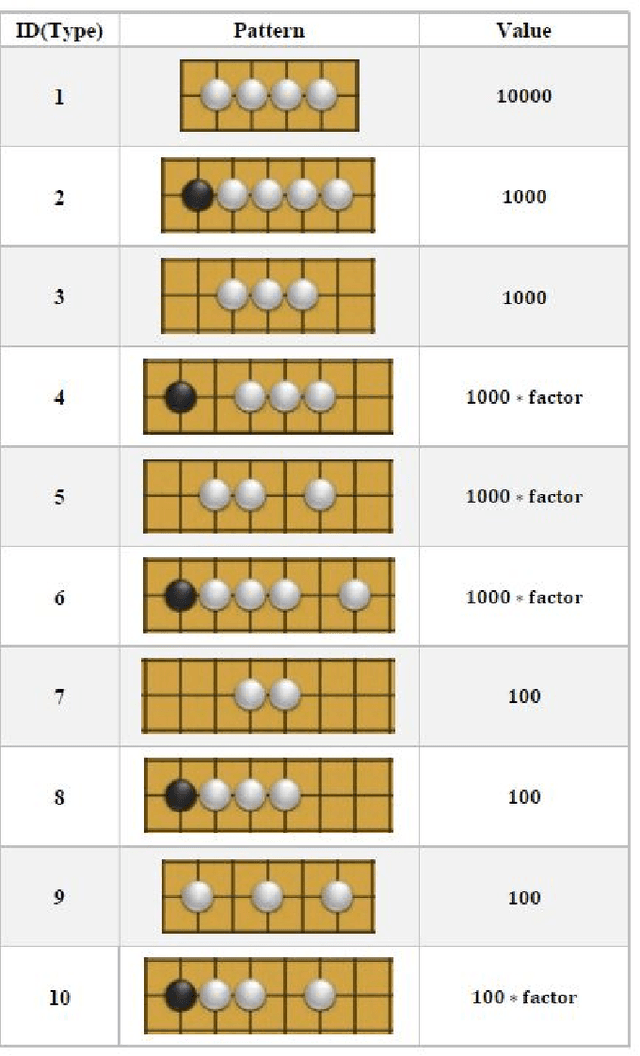
We combine Adaptive Dynamic Programming (ADP), a reinforcement learning method and UCB applied to trees (UCT) algorithm with a more powerful heuristic function based on Progressive Bias method and two pruning strategies for a traditional board game Gomoku. For the Adaptive Dynamic Programming part, we train a shallow forward neural network to give a quick evaluation of Gomoku board situations. UCT is a general approach in MCTS as a tree policy. Our framework use UCT to balance the exploration and exploitation of Gomoku game trees while we also apply powerful pruning strategies and heuristic function to re-select the available 2-adjacent grids of the state and use ADP instead of simulation to give estimated values of expanded nodes. Experiment result shows that this method can eliminate the search depth defect of the simulation process and converge to the correct value faster than single UCT. This approach can be applied to design new Gomoku AI and solve other Gomoku-like board game.