 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeL3 Fusion: Fast Transformed Convolutions on CPUs
Paper and Code
Dec 04, 2019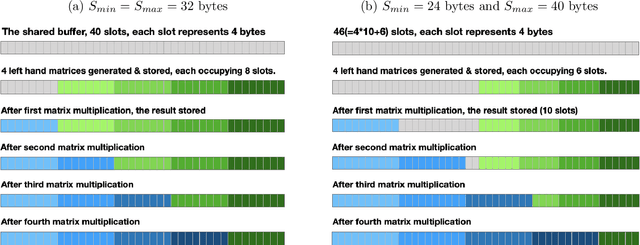
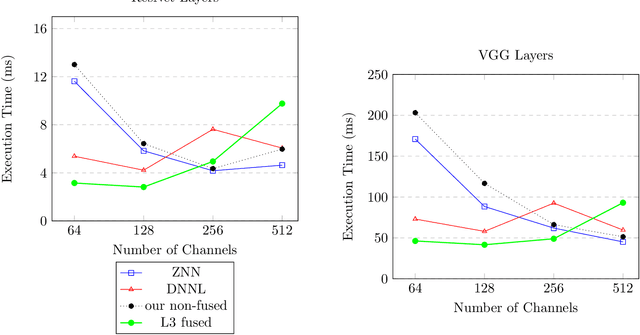
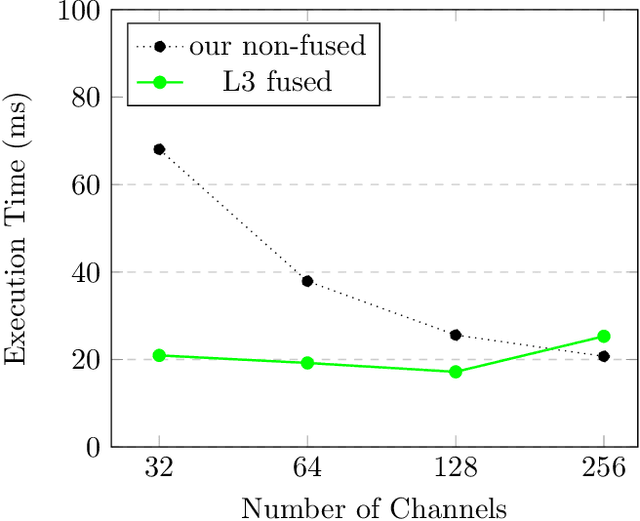
Fast convolutions via transforms, either Winograd or FFT, had emerged as a preferred way of performing the computation of convolutional layers, as it greatly reduces the number of required operations. Recent work shows that, for many layer structures, a well--designed implementation of fast convolutions can greatly utilize modern CPUs, significantly reducing the compute time. However, the generous amount of shared L3 cache present on modern CPUs is often neglected, and the algorithms are optimized solely for the private L2 cache. In this paper we propose an efficient `L3 Fusion` algorithm that is specifically designed for CPUs with significant amount of shared L3 cache. Using the hierarchical roofline model, we show that in many cases, especially for layers with fewer channels, the `L3 fused` approach can greatly outperform standard 3 stage one provided by big vendors such as Intel. We validate our theoretical findings, by benchmarking our `L3 fused` implementation against publicly available state of the art.