Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Creation of Text Corpora for Low-Resource Languages from the Internet: The Case of Swiss German
Paper and Code
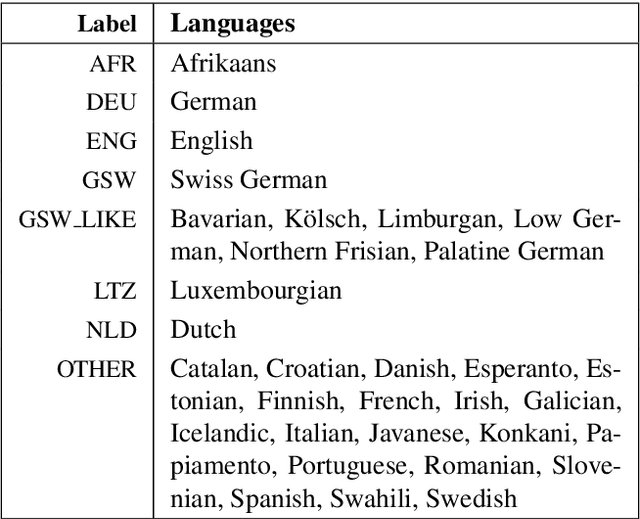
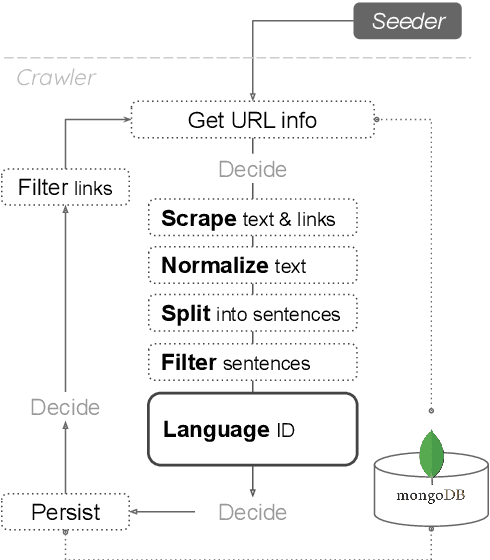
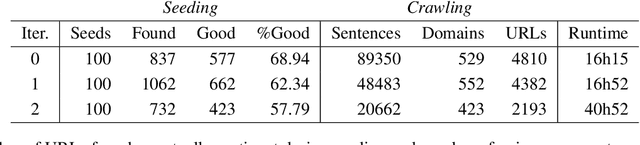
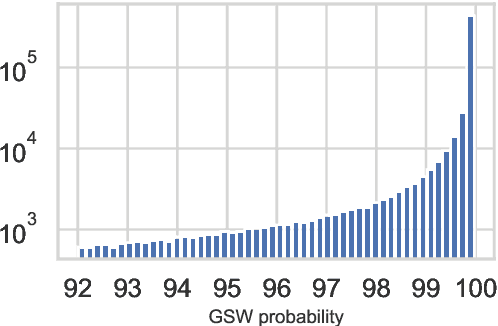
This paper presents SwissCrawl, the largest Swiss German text corpus to date. Composed of more than half a million sentences, it was generated using a customized web scraping tool that could be applied to other low-resource languages as well. The approach demonstrates how freely available web pages can be used to construct comprehensive text corpora, which are of fundamental importance for natural language processing. In an experimental evaluation, we show that using the new corpus leads to significant improvements for the task of language modeling. To capture new content, our approach will run continuously to keep increasing the corpus over time.
* Submitted to LREC 2020
View paper on