 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Deep Architectures for Head Motion Prediction in 360° Videos
Paper and Code
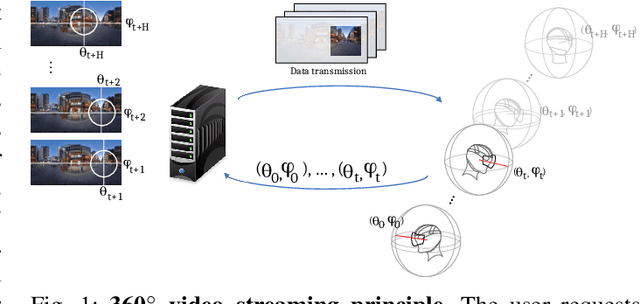
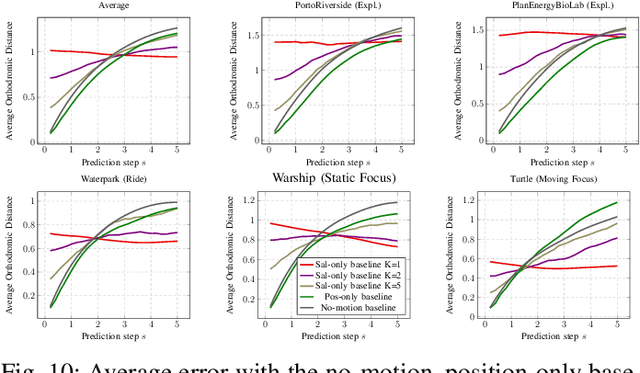
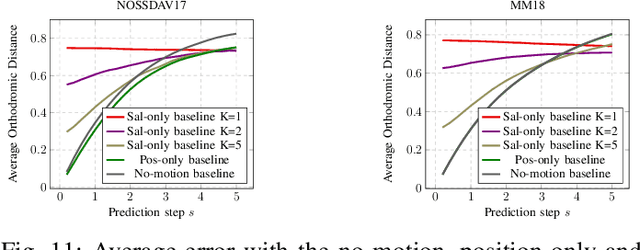
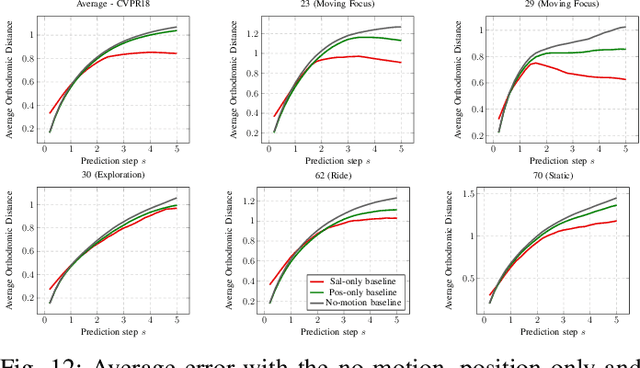
Head motion prediction is an important problem with 360\degree\ videos, in particular to inform the streaming decisions. Various methods tackling this problem with deep neural networks have been proposed recently. In this article we first show the startling result that all such existing methods, which attempt to benefit both from the history of past positions and knowledge of the video content, perform worse than a simple no-motion baseline. We then propose an LSTM-based architecture which processes the positional information only. It is able to establish state-of-the-art performance and we consider it our position-only baseline. Through a thorough root cause analysis, we first show that the content can indeed inform the head position prediction for horizons longer than 2 to 3s, the trajectory inertia being predominant earlier. We also identify that a sequence-to-sequence auto-regressive framework is crucial to improve the prediction accuracy over longer prediction windows, and that a dedicated recurrent network handling the time series of positions is necessary to reach the performance of the position-only baseline in the early prediction steps. This allows to make the most of the positional information and ground-truth saliency. Finally we show how the level of noise in the estimated saliency impacts the architecture's performance, and we propose a new architecture establishing state-of-the-art performance with estimated saliency, supporting its assets with an ablation study.