 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMerging Deterministic Policy Gradient Estimations with Varied Bias-Variance Tradeoff for Effective Deep Reinforcement Learning
Paper and Code
Nov 24, 2019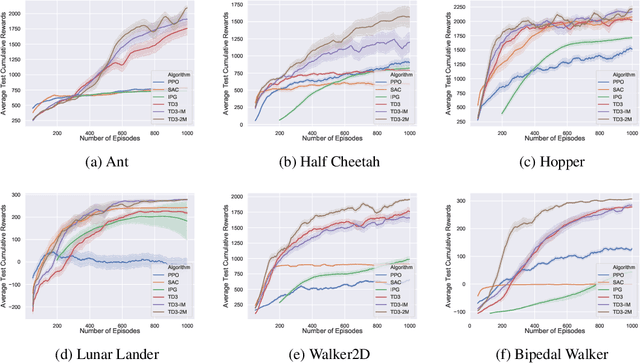
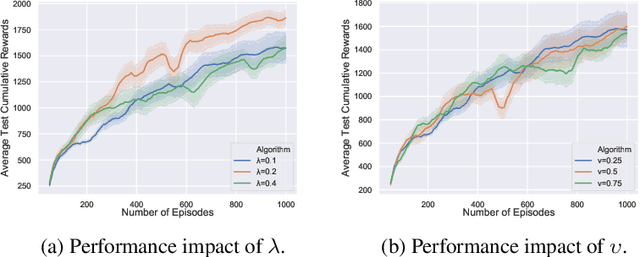
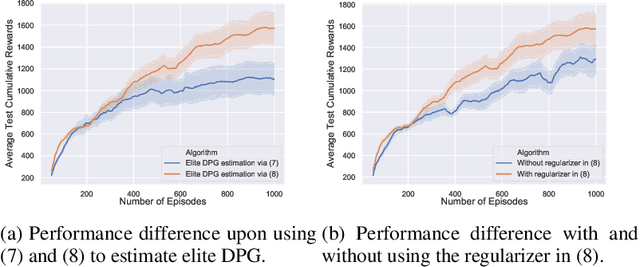
Deep reinforcement learning (DRL) on Markov decision processes (MDPs) with continuous action spaces is often approached by directly updating parametric policies along the direction of estimated policy gradients (PGs). Previous research revealed that the performance of these PG algorithms depends heavily on the bias-variance tradeoff involved in estimating and using PGs. A notable approach towards balancing this tradeoff is to merge both on-policy and off-policy gradient estimations for the purpose of training stochastic policies. However this method cannot be utilized directly by sample-efficient off-policy PG algorithms such as Deep Deterministic Policy Gradient (DDPG) and twin-delayed DDPG (TD3), which have been designed to train deterministic policies. It is hence important to develop new techniques to merge multiple off-policy estimations of deterministic PG (DPG). Driven by this research question, this paper introduces elite DPG which will be estimated differently from conventional DPG to emphasize on the variance reduction effect at the expense of increased learning bias. To mitigate the extra bias, policy consolidation techniques will be developed to distill policy behavioral knowledge from elite trajectories and use the distilled generative model to further regularize policy training. Moreover, we will study both theoretically and experimentally two different DPG merging methods, i.e., interpolation merging and two-step merging, with the aim to induce varied bias-variance tradeoff through combined use of both conventional DPG and elite DPG. Experiments on six benchmark control tasks confirm that these two merging methods can noticeably improve the learning performance of TD3, significantly outperforming several state-of-the-art DRL algorithms.