 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStage-based Hyper-parameter Optimization for Deep Learning
Paper and Code
Nov 24, 2019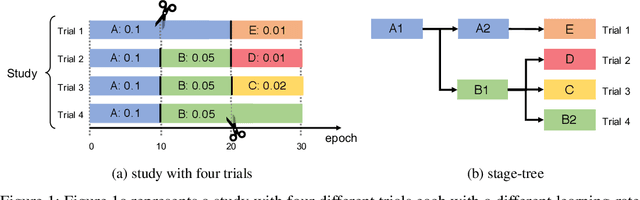

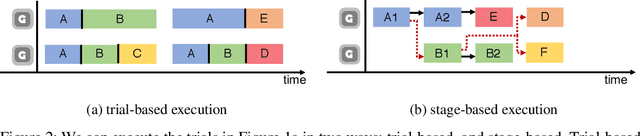
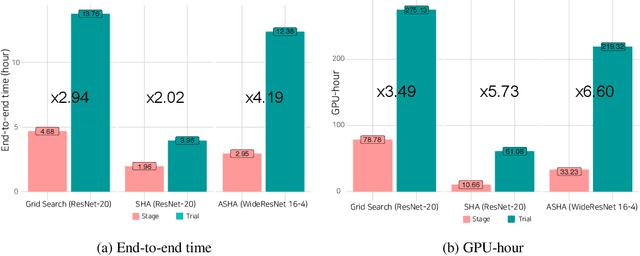
As deep learning techniques advance more than ever, hyper-parameter optimization is the new major workload in deep learning clusters. Although hyper-parameter optimization is crucial in training deep learning models for high model performance, effectively executing such a computation-heavy workload still remains a challenge. We observe that numerous trials issued from existing hyper-parameter optimization algorithms share common hyper-parameter sequence prefixes, which implies that there are redundant computations from training the same hyper-parameter sequence multiple times. We propose a stage-based execution strategy for efficient execution of hyper-parameter optimization algorithms. Our strategy removes redundancy in the training process by splitting the hyper-parameter sequences of trials into homogeneous stages, and generating a tree of stages by merging the common prefixes. Our preliminary experiment results show that applying stage-based execution to hyper-parameter optimization algorithms outperforms the original trial-based method, saving required GPU-hours and end-to-end training time by up to 6.60 times and 4.13 times, respectively.