 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient decorrelation of features using Gramian in Reinforcement Learning
Paper and Code
Nov 19, 2019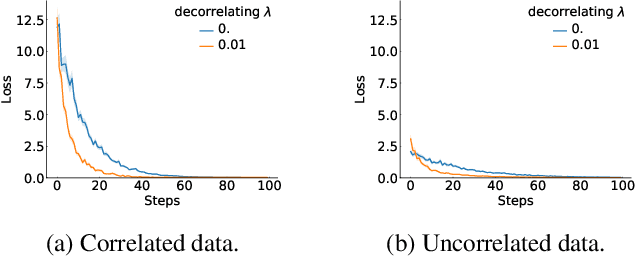
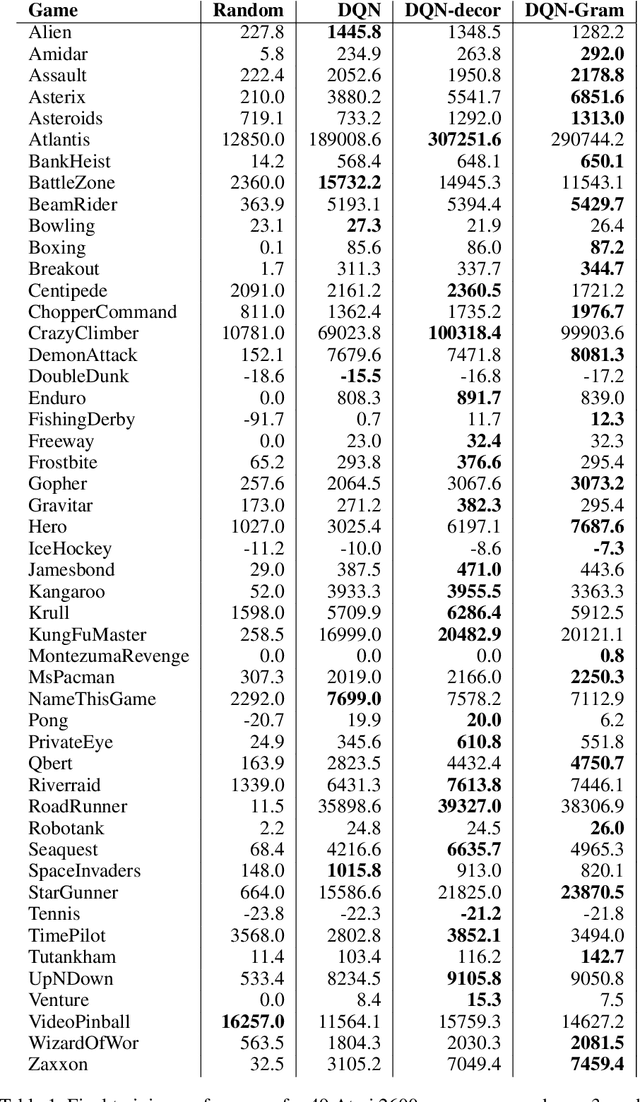
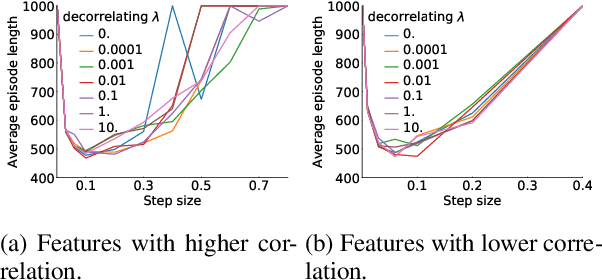
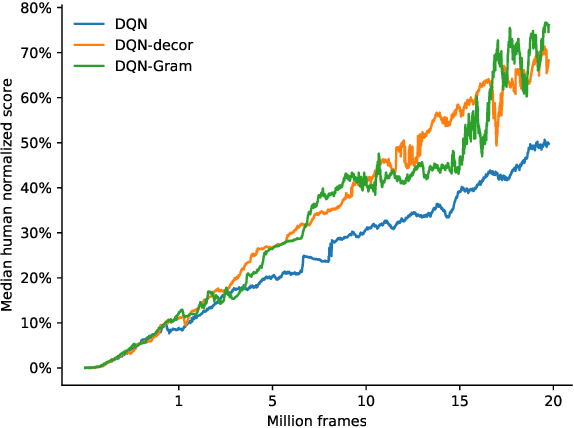
Learning good representations is a long standing problem in reinforcement learning (RL). One of the conventional ways to achieve this goal in the supervised setting is through regularization of the parameters. Extending some of these ideas to the RL setting has not yielded similar improvements in learning. In this paper, we develop an online regularization framework for decorrelating features in RL and demonstrate its utility in several test environments. We prove that the proposed algorithm converges in the linear function approximation setting and does not change the main objective of maximizing cumulative reward. We demonstrate how to scale the approach to deep RL using the Gramian of the features achieving linear computational complexity in the number of features and squared complexity in size of the batch. We conduct an extensive empirical study of the new approach on Atari 2600 games and show a significant improvement in sample efficiency in 40 out of 49 games.