 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlacement Optimization of Aerial Base Stations with Deep Reinforcement Learning
Paper and Code
Nov 19, 2019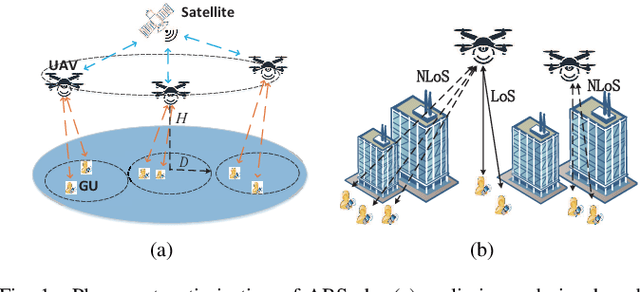
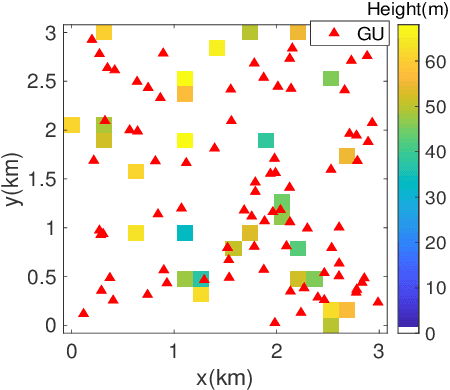
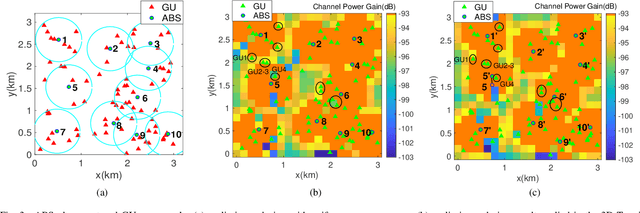
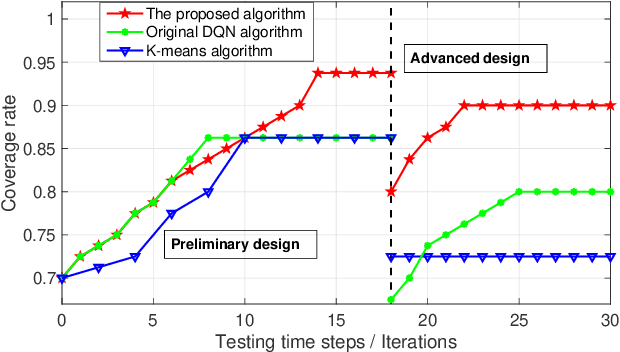
Unmanned aerial vehicles (UAVs) can be utilized as aerial base stations (ABSs) to assist terrestrial infrastructure for keeping wireless connectivity in various emergency scenarios. To maximize the coverage rate of N ground users (GUs) by jointly placing multiple ABSs with limited coverage range is known to be a NP-hard problem with exponential complexity in N. The problem is further complicated when the coverage range becomes irregular due to site-specific blockage (e.g., buildings) on the air-ground channel in the 3-dimensional (3D) space. To tackle this challenging problem, this paper applies the Deep Reinforcement Learning (DRL) method by 1) representing the state by a coverage bitmap to capture the spatial correlation of GUs/ABSs, whose dimension and associated neural network complexity is invariant with arbitrarily large N; and 2) designing the action and reward for the DRL agent to effectively learn from the dynamic interactions with the complicated propagation environment represented by a 3D Terrain Map. Specifically, a novel two-level design approach is proposed, consisting of a preliminary design based on the dominant line-of-sight (LoS) channel model, and an advanced design to further refine the ABS positions based on site-specific LoS/non-LoS channel states. The double deep Q-network (DQN) with Prioritized Experience Replay (Prioritized Replay DDQN) algorithm is applied to train the policy of multi-ABS placement decision. Numerical results show that the proposed approach significantly improves the coverage rate in complex environment, compared to the benchmark DQN and K-means algorithms.