 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegmentation Guided Attention Network for Crowd Counting via Curriculum Learning
Paper and Code
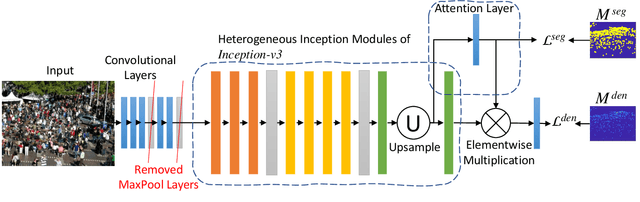
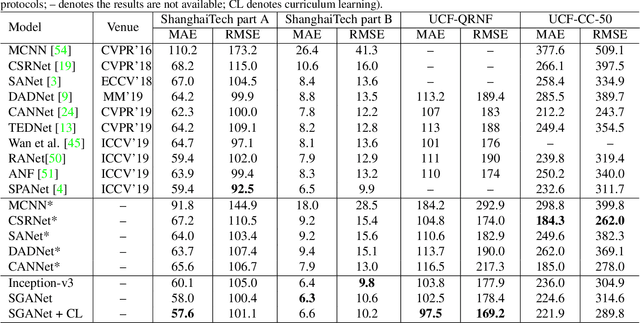
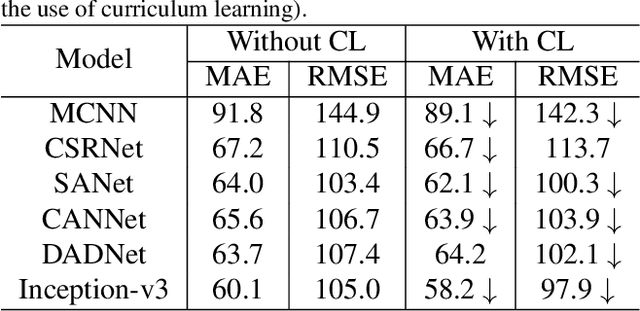
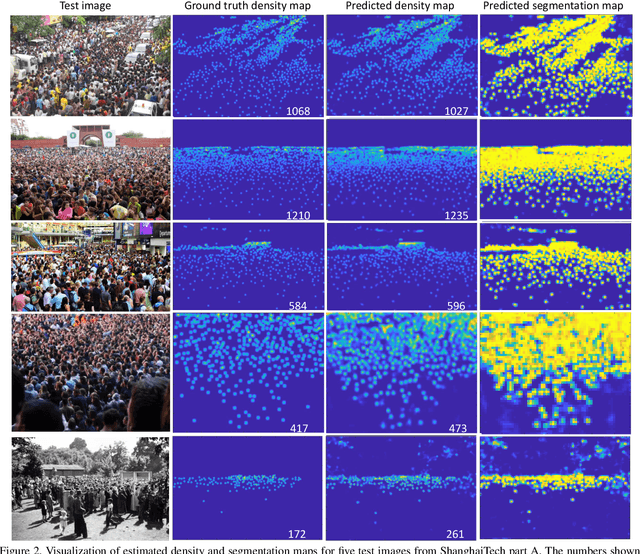
Crowd counting using deep convolutional neural networks (CNN) has achieved encouraging progress in the last couple of years. Novel network architectures have been designed to handle the scale variance issue in crowd images. For this purpose, the ideas of using multi-column networks with different convolution kernel sizes and rich feature fusion have been prevalent in literature. Recent works have shown the effectiveness of \textit{Inception} modules in crowd counting due to its ability to capture multi-scale visual information via the fusion of features from multi-column networks. However, the existing crowd counting networks built with \textit{Inception} modules usually have a small number of layers and only employ the basic type of \textit{Inception} modules. In this paper, we investigate the use of pre-trained \textit{Inception} model for crowd counting. Specifically, we firstly benchmark the baseline \textit{Inception-v3} models on commonly used crowd counting datasets and show its superiority to other existing models. Subsequently, we present a Segmentation Guided Attention Network (SGANet) with the \textit{Inception-v3} as the backbone for crowd counting. We also propose a novel curriculum learning strategy for more efficient training of crowd counting networks. Finally, we conduct thorough experiments to compare the performance of SGANet and other state-of-the-art models. The experimental results validate the effectiveness of the segmentation guided attention layer and the curriculum learning strategy in crowd counting.