 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation-Theoretic Perspective of Federated Learning
Paper and Code
Nov 15, 2019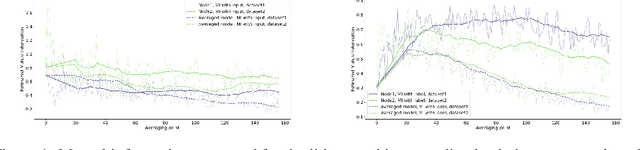
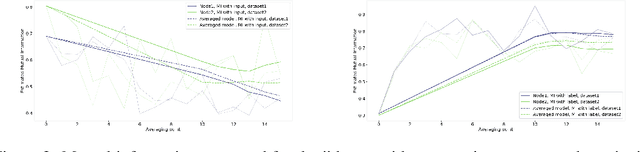
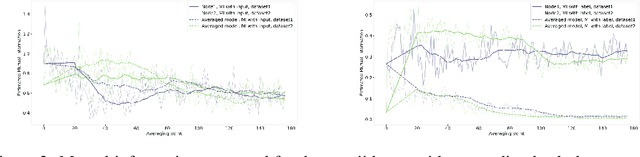
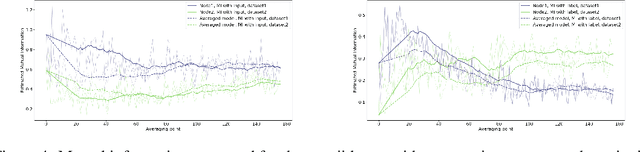
An approach to distributed machine learning is to train models on local datasets and aggregate these models into a single, stronger model. A popular instance of this form of parallelization is federated learning, where the nodes periodically send their local models to a coordinator that aggregates them and redistributes the aggregation back to continue training with it. The most frequently used form of aggregation is averaging the model parameters, e.g., the weights of a neural network. However, due to the non-convexity of the loss surface of neural networks, averaging can lead to detrimental effects and it remains an open question under which conditions averaging is beneficial. In this paper, we study this problem from the perspective of information theory: We measure the mutual information between representation and inputs as well as representation and labels in local models and compare it to the respective information contained in the representation of the averaged model. Our empirical results confirm previous observations about the practical usefulness of averaging for neural networks, even if local dataset distributions vary strongly. Furthermore, we obtain more insights about the impact of the aggregation frequency on the information flow and thus on the success of distributed learning. These insights will be helpful both in improving the current synchronization process and in further understanding the effects of model aggregation.