 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSystematic Comparison of the Influence of Different Data Preprocessing Methods on the Classification of Gait Using Machine Learning
Paper and Code
Nov 11, 2019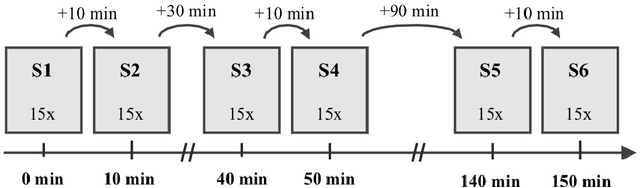
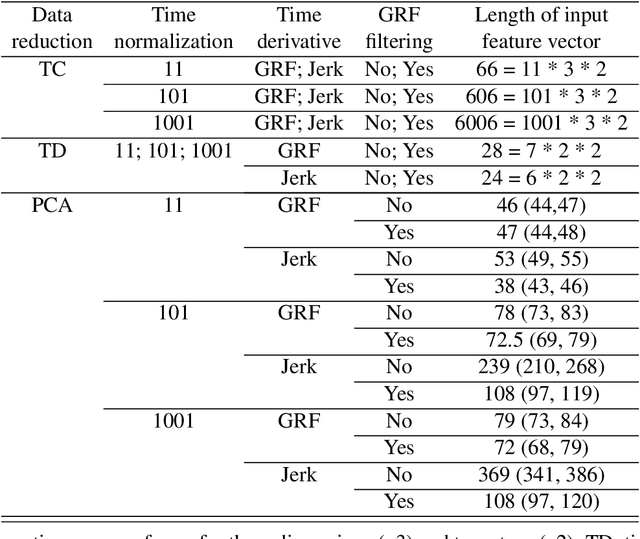
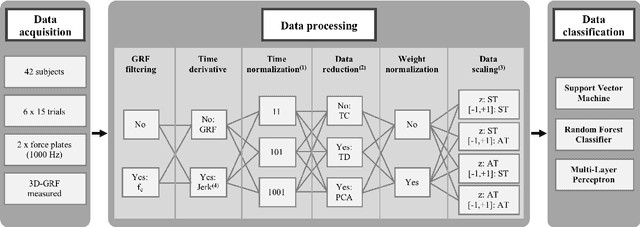
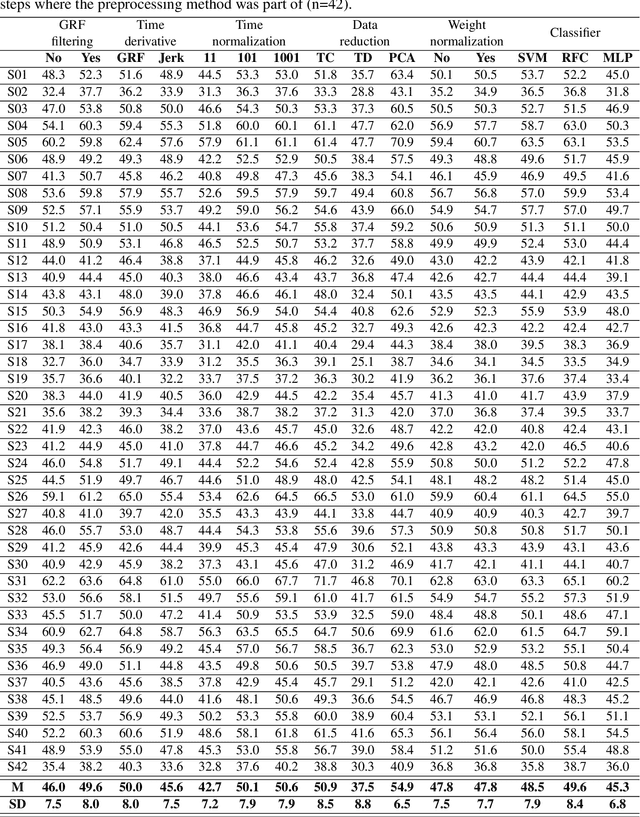
Human movements are characterized by highly non-linear and multi-dimensional interactions within the motor system. Recently, an increasing emphasis on machine-learning applications has led to a significant contribution to the field of gait analysis e.g. in increasing the classification accuracy. In order to ensure the generalizability of the machine-learning models, different data preprocessing steps are usually carried out to process the measured raw data before the classifications. In the past, various methods have been used for each of these preprocessing steps. However, there are hardly any standard procedures or rather systematic comparisons of these different methods and their impact on the classification accuracy. Therefore, the aim of this analysis is to compare different combinations of commonly applied data preprocessing steps and test their effects on the classification accuracy of gait patterns. A publicly available dataset on intra-individual changes of gait patterns was used for this analysis. Forty-two healthy subjects performed 6 sessions of 15 gait trials for one day. For each trial, two force plates recorded the 3D ground reaction forces (GRF). The data was preprocessed with the following steps: GRF filtering, time derivative, time normalization, data reduction, weight normalization and data scaling. Subsequently, combinations of all methods from each individual preprocessing step were analyzed and compared with respect to their prediction accuracy in a six-session classification using Support Vector Machines, Random Forest Classifiers and Multi-Layer Perceptrons. In conclusion, the present results provide first domain-specific recommendations for commonly applied data preprocessing methods and might help to build more comparable and more robust classification models based on machine learning that are suitable for a practical application.