 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Decoding Strategies Affect the Verifiability of Generated Text
Paper and Code
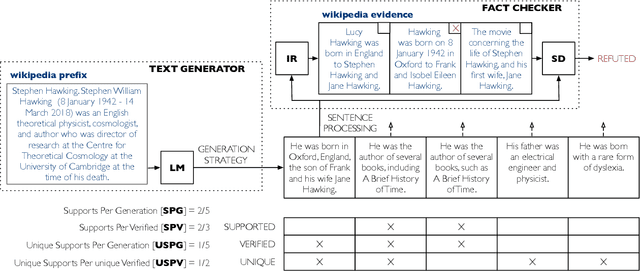
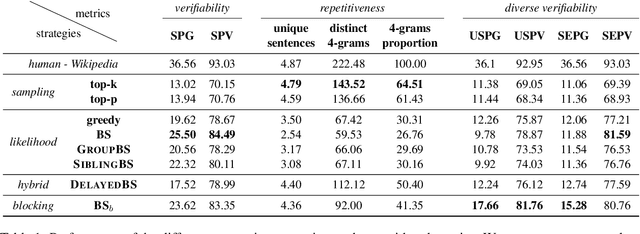
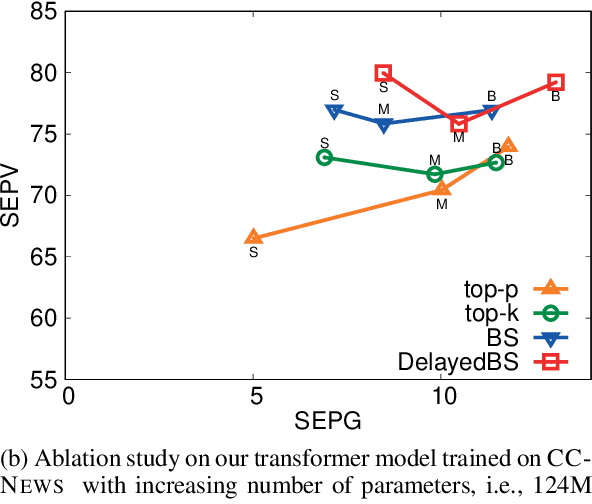

Language models are of considerable importance. They are used for pretraining, finetuning, and rescoring in downstream applications, and as is as a test-bed and benchmark for progress in natural language understanding. One fundamental question regards the way we should generate text from a language model. It is well known that different decoding strategies can have dramatic impact on the quality of the generated text and using the most likely sequence under the model distribution, e.g., via beam search, generally leads to degenerate and repetitive outputs. While generation strategies such as top-k and nucleus sampling lead to more natural and less repetitive generations, the true cost of avoiding the highest scoring solution is hard to quantify. In this paper, we argue that verifiability, i.e., the consistency of the generated text with factual knowledge, is a suitable metric for measuring this cost. We use an automatic fact-checking system to calculate new metrics as a function of the number of supported claims per sentence and find that sampling-based generation strategies, such as top-k, indeed lead to less verifiable text. This finding holds across various dimensions, such as model size, training data size and parameters of the generation strategy. Based on this finding, we introduce a simple and effective generation strategy for producing non-repetitive and more verifiable (in comparison to other methods) text.