 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph-to-Graph Transformer for Transition-based Dependency Parsing
Paper and Code
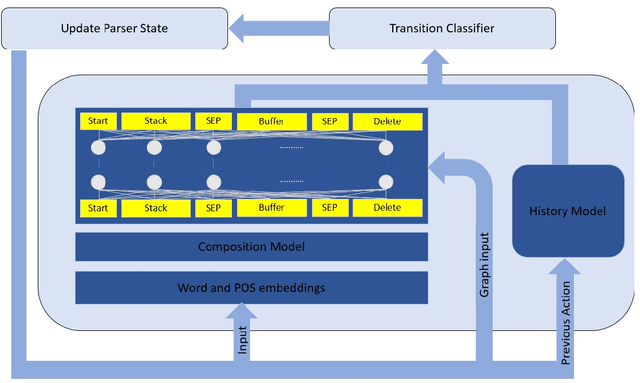
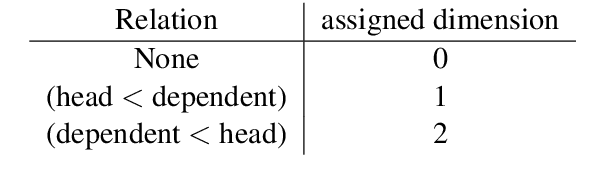
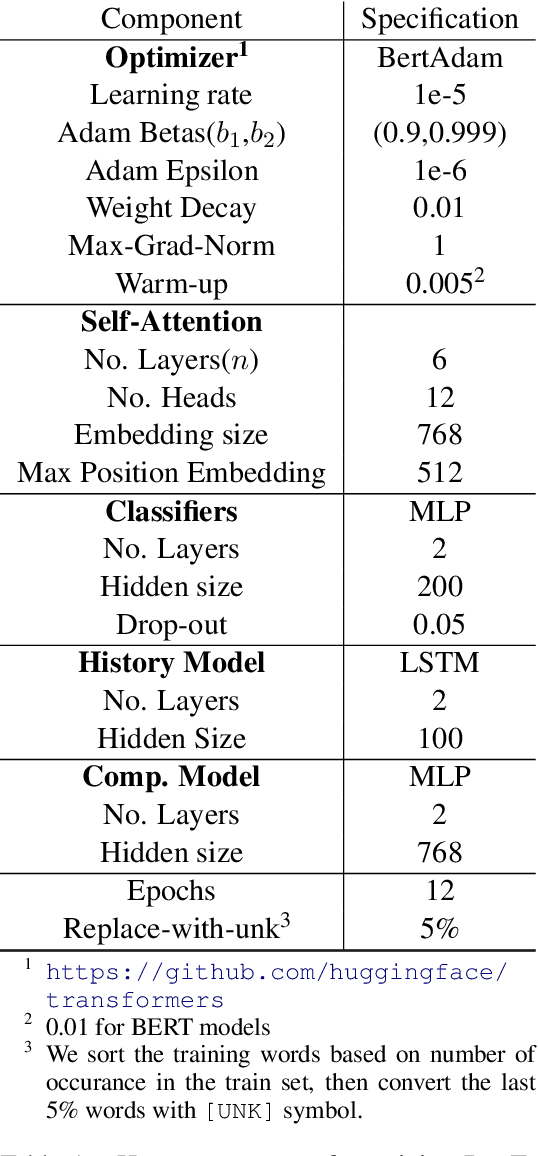
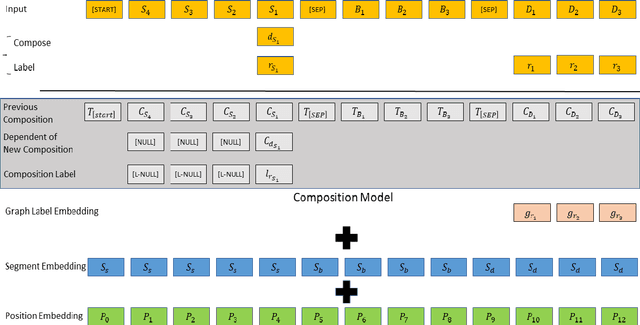
Transition-based dependency parsing is a challenging task for conditioning on and predicting structures. We demonstrate state-of-the-art results on this benchmark with the Graph2Graph Transformer architecture. This novel architecture supports both the input and output of arbitrary graphs via its attention mechanism. It can also be integrated both with previous neural network structured prediction techniques and with existing Transformer pre-trained models. Both with and without BERT pretraining, adding dependency graph inputs via the attention mechanism results in significant improvements over previously proposed mechanism for encoding the partial parse tree, resulting in accuracies which improve the state-of-the-art in transition-based dependency parsing, achieving 95.64% UAS and 93.81% LAS performance on Stanford WSJ dependencies. Graph2Graph Transformers are not restricted to tree structures and can be easily applied to a wide range of NLP tasks.