 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTheoretical Guarantees for Model Auditing with Finite Adversaries
Paper and Code
Nov 08, 2019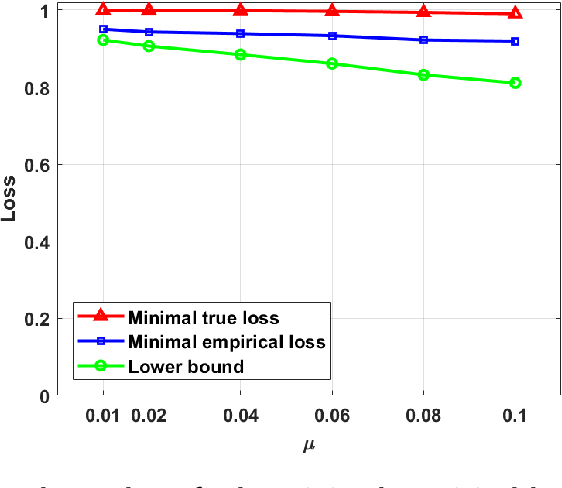
Privacy concerns have led to the development of privacy-preserving approaches for learning models from sensitive data. Yet, in practice, even models learned with privacy guarantees can inadvertently memorize unique training examples or leak sensitive features. To identify such privacy violations, existing model auditing techniques use finite adversaries defined as machine learning models with (a) access to some finite side information (e.g., a small auditing dataset), and (b) finite capacity (e.g., a fixed neural network architecture). Our work investigates the requirements under which an unsuccessful attempt to identify privacy violations by a finite adversary implies that no stronger adversary can succeed at such a task. We do so via parameters that quantify the capabilities of the finite adversary, including the size of the neural network employed by such an adversary and the amount of side information it has access to as well as the regularity of the (perhaps privacy-guaranteeing) audited model.