 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtracting temporal features into a spatial domain using autoencoders for sperm video analysis
Paper and Code
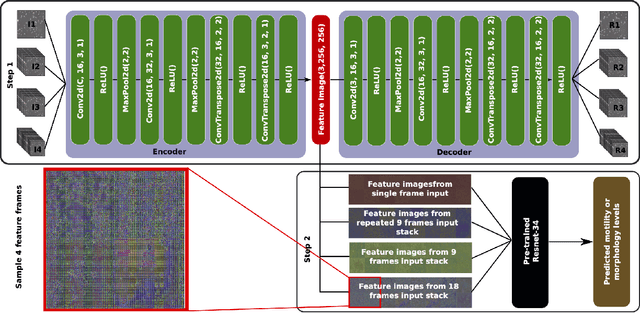
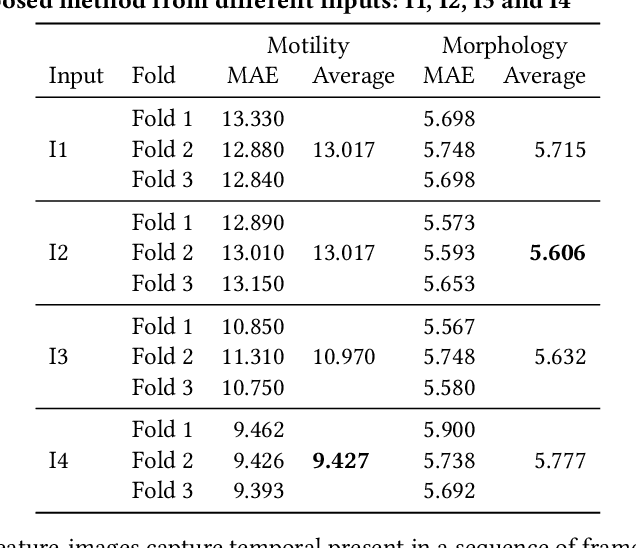
In this paper, we present a two-step deep learning method that is used to predict sperm motility and morphology-based on video recordings of human spermatozoa. First, we use an autoencoder to extract temporal features from a given semen video and plot these into image-space, which we call feature-images. Second, these feature-images are used to perform transfer learning to predict the motility and morphology values of human sperm. The presented method shows it's capability to extract temporal information into spatial domain feature-images which can be used with traditional convolutional neural networks. Furthermore, the accuracy of the predicted motility of a given semen sample shows that a deep learning-based model can capture the temporal information of microscopic recordings of human semen.