 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoverage-based Outlier Explanation
Paper and Code
Nov 06, 2019
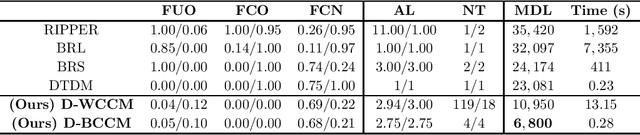

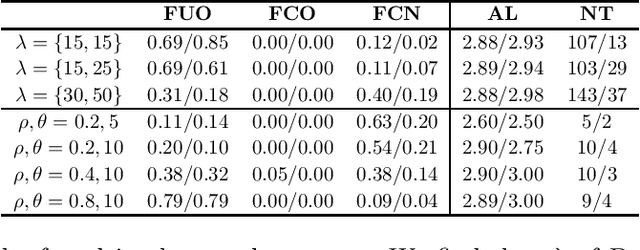
Outlier detection is a core task in data mining with a plethora of algorithms that have enjoyed wide scale usage. Existing algorithms are primarily focused on detection, that is the identification of outliers in a given dataset. In this paper we explore the relatively under-studied problem of the outlier explanation problem. Our goal is, given a dataset that is already divided into outliers and normal instances, explain what characterizes the outliers. We explore the novel direction of a semantic explanation that a domain expert or policy maker is able to understand. We formulate this as an optimization problem to find explanations that are both interpretable and pure. Through experiments on real-world data sets, we quantitatively show that our method can efficiently generate better explanations compared with rule-based learners.