 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Residual Dipolar Couplings from Two Alignment Media to Detect Structural Homology
Paper and Code
Nov 06, 2019

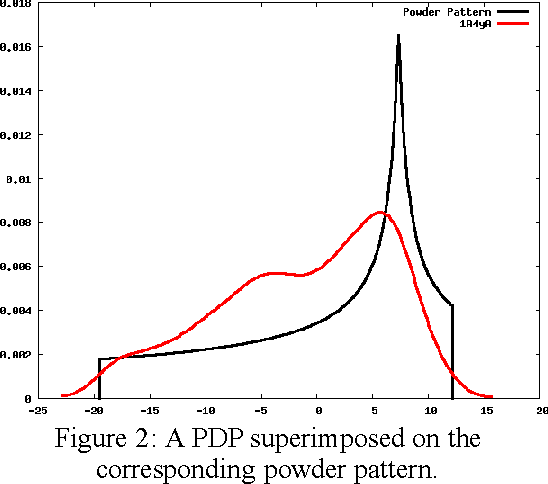
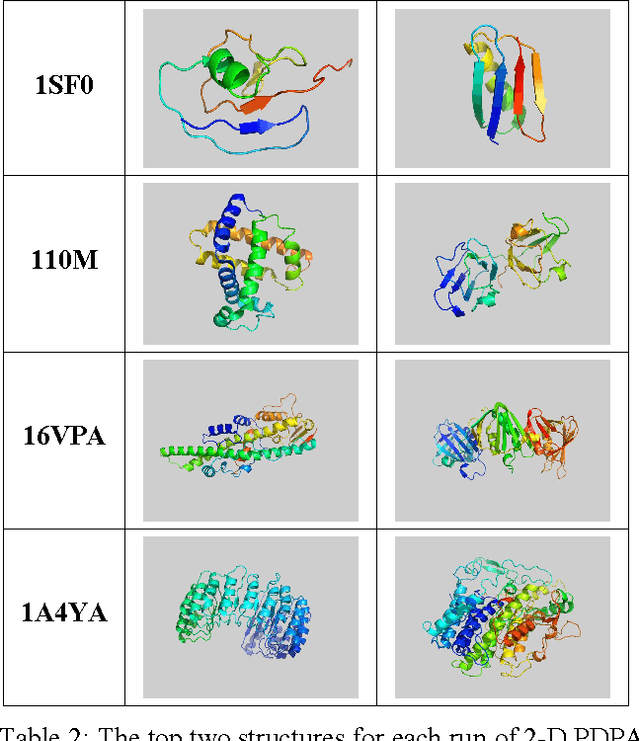
The method of Probability Density Profile Analysis has been introduced previously as a tool to find the best match between a set of experimentally generated Residual Dipolar Couplings and a set of known protein structures. While it proved effective on small databases in identifying protein fold families, and for picking the best result from computational protein folding tool ROBETTA, for larger data sets, more data is required. Here, the method of 2-D Probability Density Profile Analysis is presented which incorporates paired RDC data from 2 alignment media for N-H vectors. The method was tested using synthetic RDC data generated with +/-1 Hz error. The results show that the addition of information from a second alignment medium makes 2-D PDPA a much more effective tool that is able to identify a structure from a database of 600 protein fold family representatives.