 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProtein Fold Family Recognition From Unassigned Residual Dipolar Coupling Data
Paper and Code
Nov 01, 2019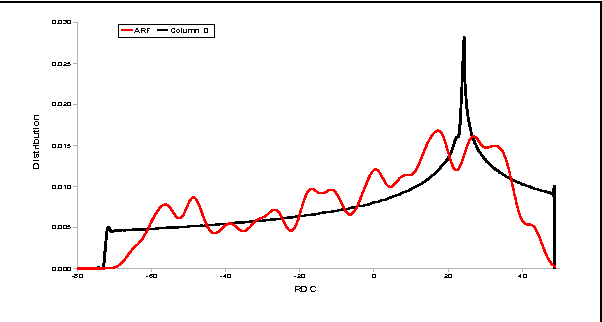
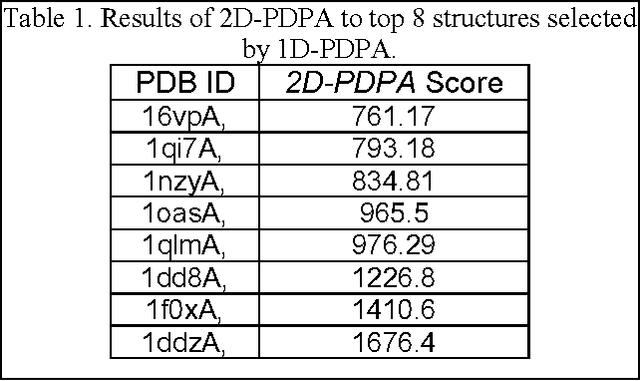
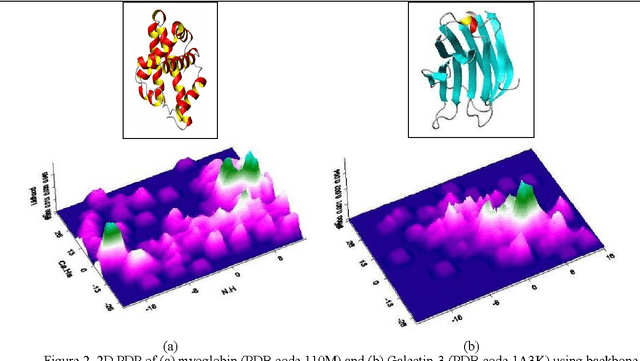
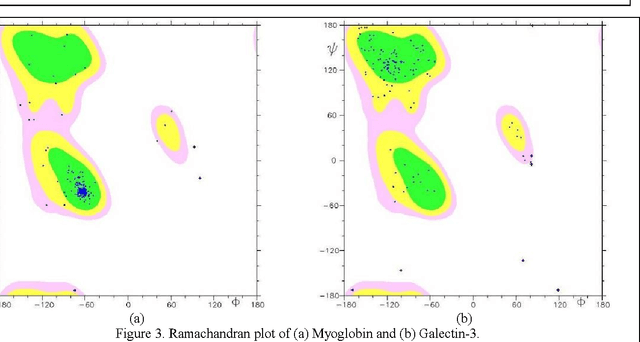
Despite many advances in computational modeling of protein structures, these methods have not been widely utilized by experimental structural biologists. Two major obstacles are preventing the transition from a purely-experimental to a purely-computational mode of protein structure determination. The first problem is that most computational methods need a large library of computed structures that span a large variety of protein fold families, while structural genomics initiatives have slowed in their ability to provide novel protein folds in recent years. The second problem is an unwillingness to trust computational models that have no experimental backing. In this paper we test a potential solution to these problems that we have called Probability Density Profile Analysis (PDPA) that utilizes unassigned residual dipolar coupling data that are relatively cheap to acquire from NMR experiments.