 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-label Co-regularization for Semi-supervised Facial Action Unit Recognition
Paper and Code
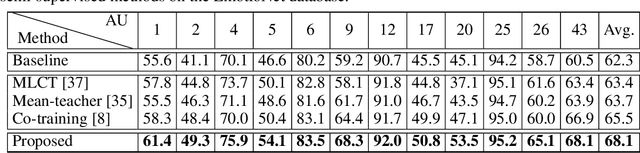
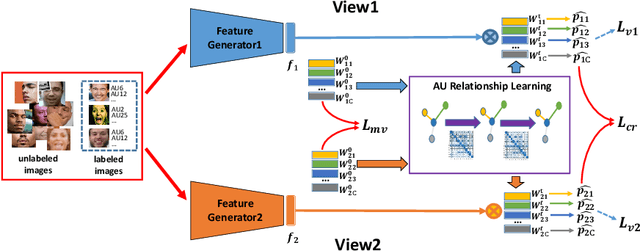
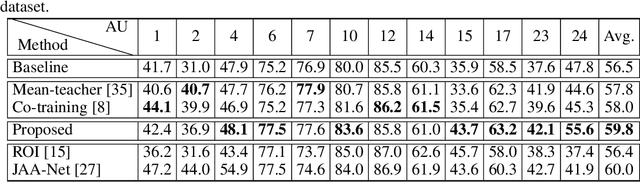
Facial action units (AUs) recognition is essential for emotion analysis and has been widely applied in mental state analysis. Existing work on AU recognition usually requires big face dataset with AU labels; however, manual AU annotation requires expertise and can be time-consuming. In this work, we propose a semi-supervised approach for AU recognition utilizing a large number of web face images without AU labels and a relatively small face dataset with AU annotations inspired by the co-training methods. Unlike traditional co-training methods that require provided multi-view features and model re-training, we propose a novel co-training method, namely multi-label co-regularization, for semi-supervised facial AU recognition. Two deep neural networks are utilized to generate multi-view features for both labeled and unlabeled face images, and a multi-view loss is designed to enforce the two feature generators to get conditional independent representations. In order to constrain the prediction consistency of the two views, we further propose a multi-label co-regularization loss by minimizing the distance of the predicted AU probability distributions of two views. In addition, prior knowledge of the relationship between individual AUs is embedded through a graph convolutional network (GCN) for exploiting useful information from the big unlabeled dataset. Experiments on several benchmarks show that the proposed approach can effectively leverage large datasets of face images without AU labels to improve the AU recognition accuracy and outperform the state-of-the-art semi-supervised AU recognition methods.