 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeState2vec: Off-Policy Successor Features Approximators
Paper and Code
Oct 22, 2019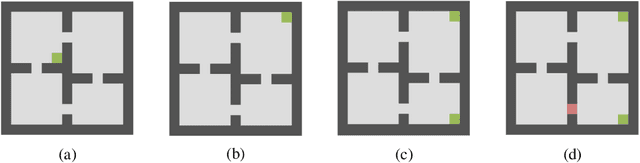
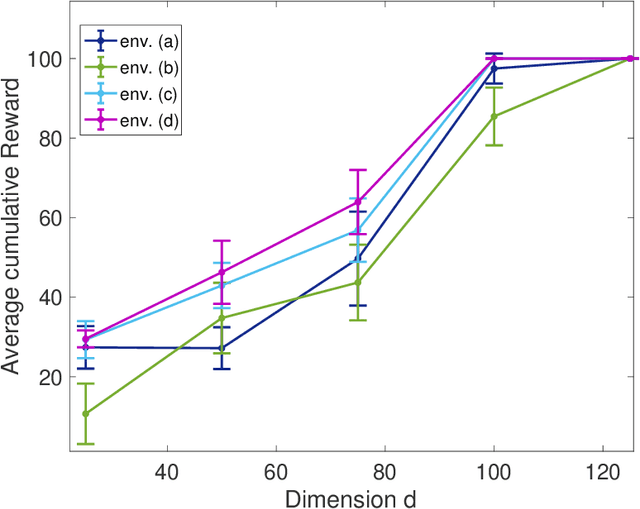
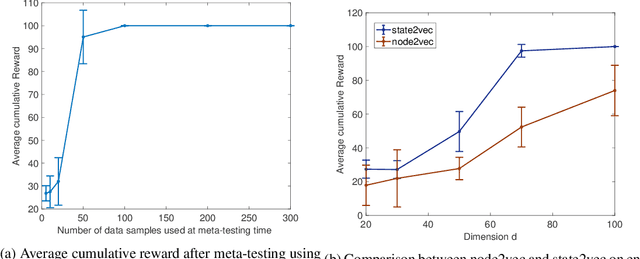
A major challenge in reinforcement learning (RL) is the design of agents that are able to generalize across tasks that share common dynamics. A viable solution is meta-reinforcement learning, which identifies common structures among past tasks to be then generalized to new tasks (meta-test). In meta-training, the RL agent learns state representations that encode prior information from a set of tasks, used to generalize the value function approximation. This has been proposed in the literature as successor representation approximators. While promising, these methods do not generalize well across optimal policies, leading to sampling-inefficiency during meta-test phases. In this paper, we propose state2vec, an efficient and low-complexity framework for learning successor features which (i) generalize across policies, (ii) ensure sample-efficiency during meta-test. We extend the well known node2vec framework to learn state embeddings that account for the discounted future state transitions in RL. The proposed off-policy state2vec captures the geometry of the underlying state space, making good basis functions for linear value function approximation.