 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal bootstrapping
Paper and Code
Oct 21, 2019
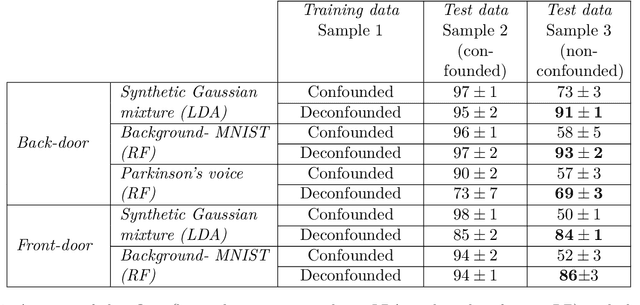
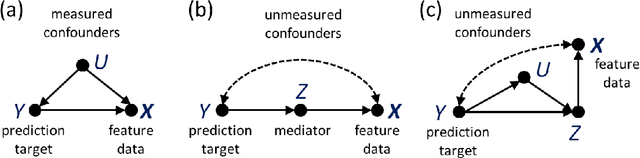
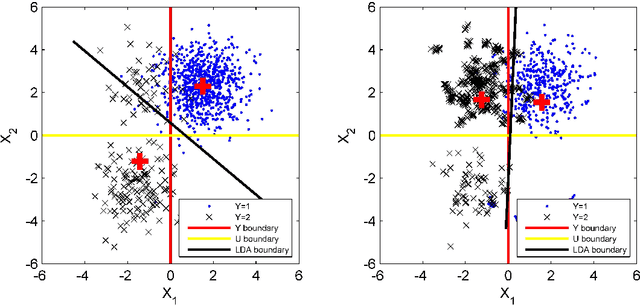
To draw scientifically meaningful conclusions and build reliable models of quantitative phenomena, cause and effect must be taken into consideration (either implicitly or explicitly). This is particularly challenging when the measurements are not from controlled experimental (interventional) settings, since cause and effect can be obscured by spurious, indirect influences. Modern predictive techniques from machine learning are capable of capturing high-dimensional, nonlinear relationships between variables while relying on few parametric or probabilistic model assumptions. However, since these techniques are associational, applied to observational data they are prone to picking up spurious influences from non-experimental (observational) data, making their predictions unreliable. Techniques from causal inference, such as probabilistic causal diagrams and do-calculus, provide powerful (nonparametric) tools for drawing causal inferences from such observational data. However, these techniques are often incompatible with modern, nonparametric machine learning algorithms since they typically require explicit probabilistic models. Here, we develop causal bootstrapping for augmenting classical nonparametric bootstrap resampling with information on the causal relationship between variables. This makes it possible to resample observational data such that, if it is possible to identify an interventional relationship from that data, new data representing that relationship can be simulated from the original observational data. In this way, we can use modern machine learning algorithms unaltered to make statistically powerful, yet causally-robust, predictions. We develop several causal bootstrapping algorithms for drawing interventional inferences from observational data, for classification and regression problems, and demonstrate, using synthetic and real-world examples, the value of this approach.