 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAll-Action Policy Gradient Methods: A Numerical Integration Approach
Paper and Code
Oct 21, 2019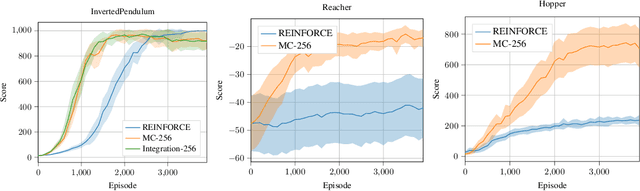
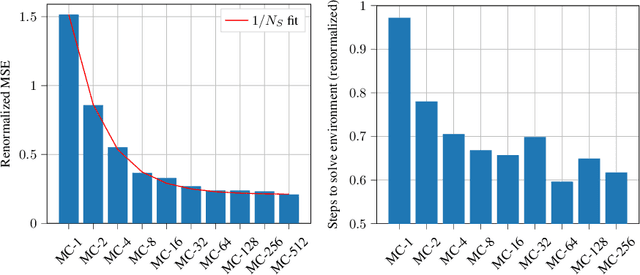
While often stated as an instance of the likelihood ratio trick [Rubinstein, 1989], the original policy gradient theorem [Sutton, 1999] involves an integral over the action space. When this integral can be computed, the resulting "all-action" estimator [Sutton, 2001] provides a conditioning effect [Bratley, 1987] reducing the variance significantly compared to the REINFORCE estimator [Williams, 1992]. In this paper, we adopt a numerical integration perspective to broaden the applicability of the all-action estimator to general spaces and to any function class for the policy or critic components, beyond the Gaussian case considered by [Ciosek, 2018]. In addition, we provide a new theoretical result on the effect of using a biased critic which offers more guidance than the previous "compatible features" condition of [Sutton, 1999]. We demonstrate the benefit of our approach in continuous control tasks with nonlinear function approximation. Our results show improved performance and sample efficiency.