 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal Text Representation from BERT: An Empirical Study
Paper and Code
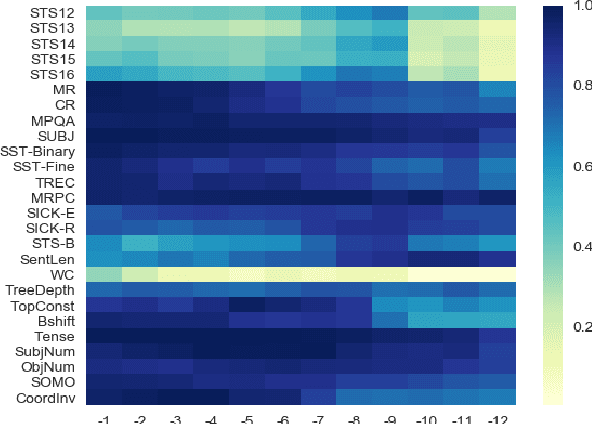
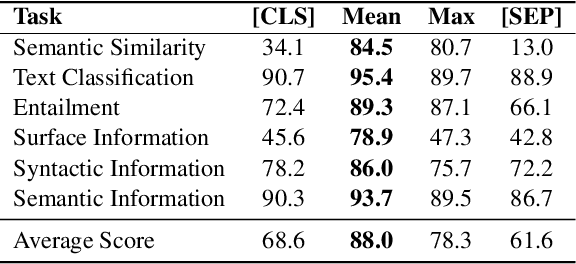
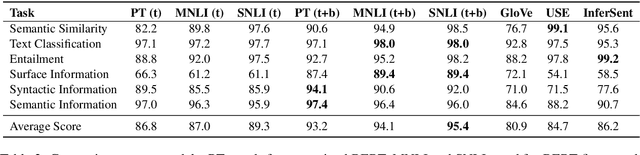
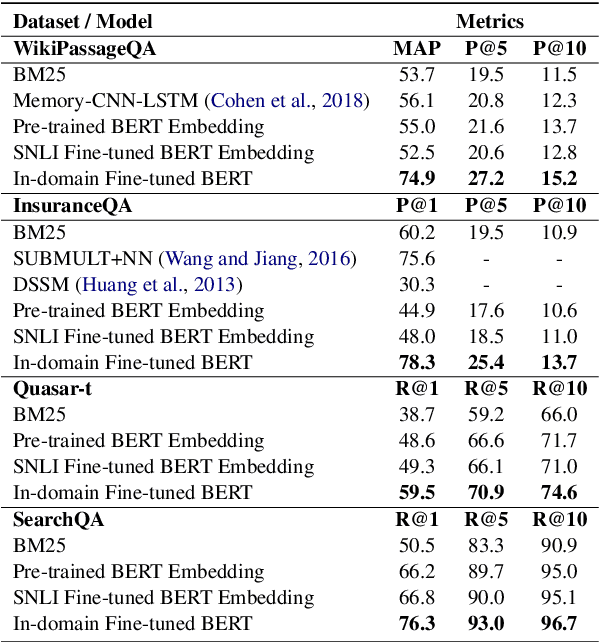
We present a systematic investigation of layer-wise BERT activations for general-purpose text representations to understand what linguistic information they capture and how transferable they are across different tasks. Sentence-level embeddings are evaluated against two state-of-the-art models on downstream and probing tasks from SentEval, while passage-level embeddings are evaluated on four question-answering (QA) datasets under a learning-to-rank problem setting. Embeddings from the pre-trained BERT model perform poorly in semantic similarity and sentence surface information probing tasks. Fine-tuning BERT on natural language inference data greatly improves the quality of the embeddings. Combining embeddings from different BERT layers can further boost performance. BERT embeddings outperform BM25 baseline significantly on factoid QA datasets at the passage level, but fail to perform better than BM25 on non-factoid datasets. For all QA datasets, there is a gap between embedding-based method and in-domain fine-tuned BERT (we report new state-of-the-art results on two datasets), which suggests deep interactions between question and answer pairs are critical for those hard tasks.