 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Examples for Models of Code
Paper and Code

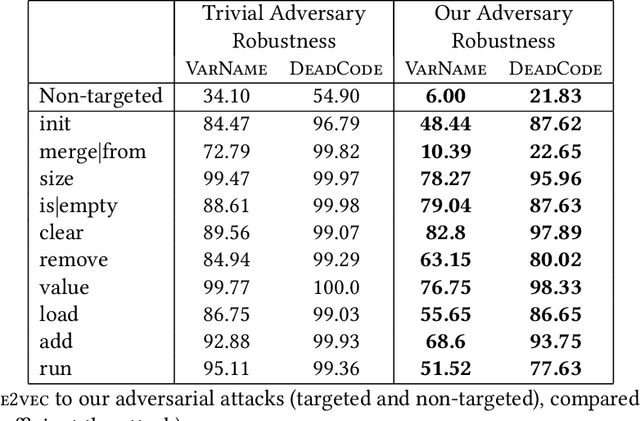
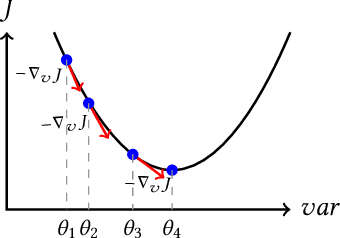
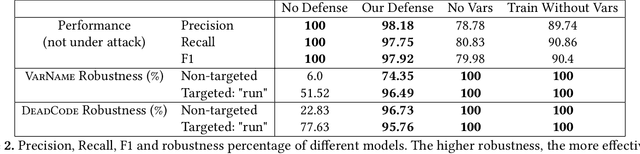
Neural models of code have shown impressive performance for tasks such as predicting method names and identifying certain kinds of bugs. In this paper, we show that these models are vulnerable to adversarial examples, and introduce a novel approach for attacking trained models of code with adversarial examples. The main idea is to force a given trained model to make an incorrect prediction as specified by the adversary by introducing small perturbations that do not change the program's semantics. To find such perturbations, we present a new technique for Discrete Adversarial Manipulation of Programs (DAMP). DAMP works by deriving the desired prediction with respect to the model's inputs while holding the model weights constant and following the gradients to slightly modify the code. To defend a model against such attacks, we propose placing a defensive model (Anti-DAMP) in front of it. Anti-DAMP detects unlikely mutations and masks them before feeding the input to the downstream model. We show that our DAMP attack is effective across three neural architectures: code2vec, GGNN, and GNN-FiLM, in both Java and C#. We show that DAMP has up to 89% success rate in changing a prediction to the adversary's choice ("targeted attack"), and a success rate of up to 94% in changing a given prediction to any incorrect prediction ("non-targeted attack"). By using Anti-DAMP, the success rate of the attack drops drastically for both targeted and non-targeted attacks, with a minor penalty of 2% relative degradation in accuracy while not performing under attack.