 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMUTE: Data-Similarity Driven Multi-hot Target Encoding for Neural Network Design
Paper and Code
Oct 15, 2019

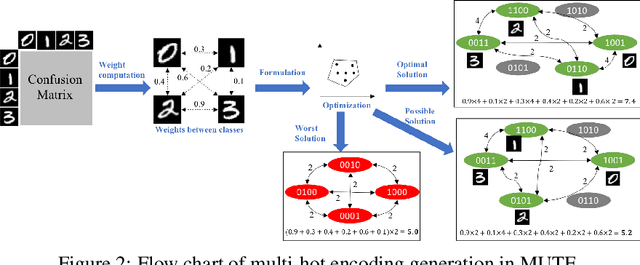
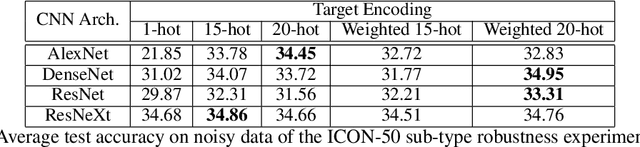
Target encoding is an effective technique to deliver better performance for conventional machine learning methods, and recently, for deep neural networks as well. However, the existing target encoding approaches require significant increase in the learning capacity, thus demand higher computation power and more training data. In this paper, we present a novel and efficient target encoding scheme, MUTE to improve both generalizability and robustness of a target model by understanding the inter-class characteristics of a target dataset. By extracting the confusion level between the target classes in a dataset, MUTE strategically optimizes the Hamming distances among target encoding. Such optimized target encoding offers higher classification strength for neural network models with negligible computation overhead and without increasing the model size. When MUTE is applied to the popular image classification networks and datasets, our experimental results show that MUTE offers better generalization and defense against the noises and adversarial attacks over the existing solutions.