 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTarget-Oriented Deformation of Visual-Semantic Embedding Space
Paper and Code
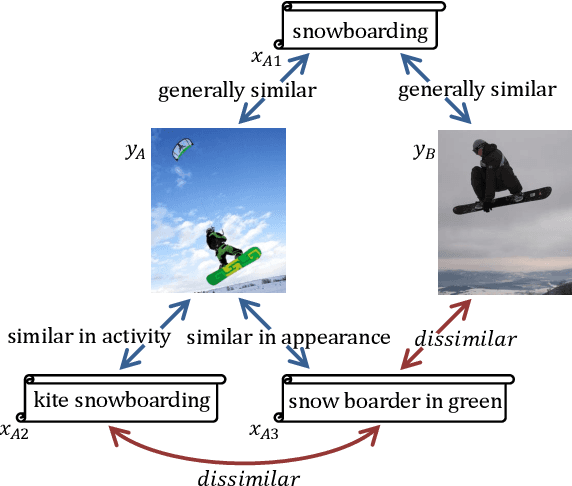
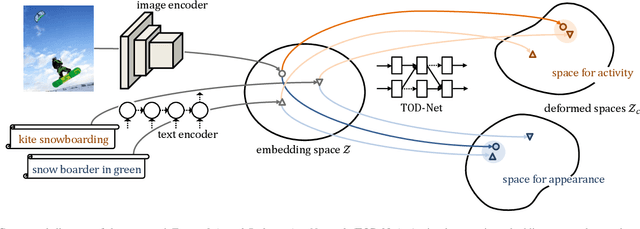
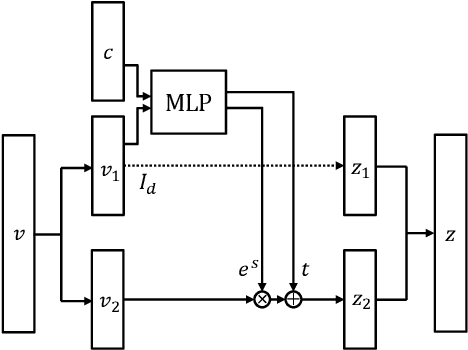
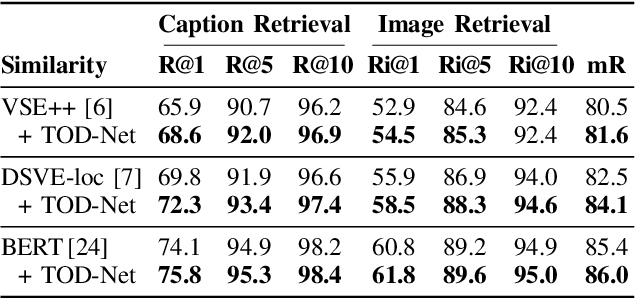
Multimodal embedding is a crucial research topic for cross-modal understanding, data mining, and translation. Many studies have attempted to extract representations from given entities and align them in a shared embedding space. However, because entities in different modalities exhibit different abstraction levels and modality-specific information, it is insufficient to embed related entities close to each other. In this study, we propose the Target-Oriented Deformation Network (TOD-Net), a novel module that continuously deforms the embedding space into a new space under a given condition, thereby adjusting similarities between entities. Unlike methods based on cross-modal attention, TOD-Net is a post-process applied to the embedding space learned by existing embedding systems and improves their performances of retrieval. In particular, when combined with cutting-edge models, TOD-Net gains the state-of-the-art cross-modal retrieval model associated with the MSCOCO dataset. Qualitative analysis reveals that TOD-Net successfully emphasizes entity-specific concepts and retrieves diverse targets via handling higher levels of diversity than existing models.