 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding the Curse of Horizon in Off-Policy Evaluation via Conditional Importance Sampling
Paper and Code
Oct 15, 2019

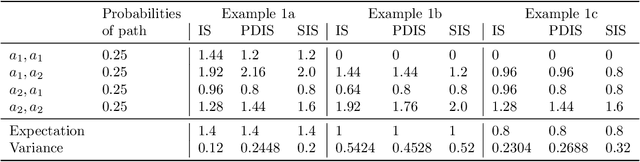
We establish a connection between the importance sampling estimators typically used for off-policy policy evaluation in reinforcement learning and the extended conditional Monte Carlo method. We show with some examples that in the finite horizon case there is no strict ordering in general between the variance of such conditional importance sampling estimators: the variance of the per-decision or stationary variants may, in fact, be higher than that of the crude importance sampling estimator. We also provide sufficient conditions for the finite horizon case under which the per-decision or stationary estimators can reduce the variance. We then develop an asymptotic analysis and derive sufficient conditions under which there exists an exponential v.s. polynomial gap (in terms of horizon $T$) between the variance of importance sampling and that of the per-decision or stationary estimators.