 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNESTA: Hamming Weight Compression-Based Neural Proc. Engine
Paper and Code
Oct 01, 2019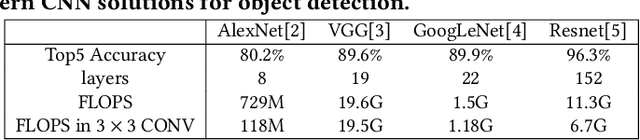
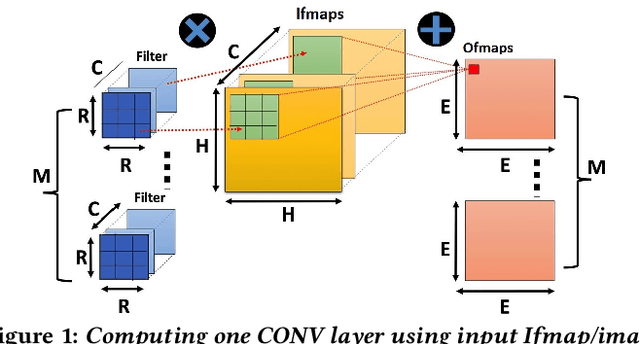
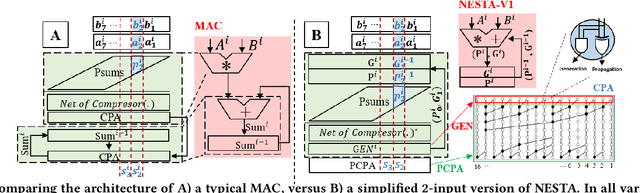
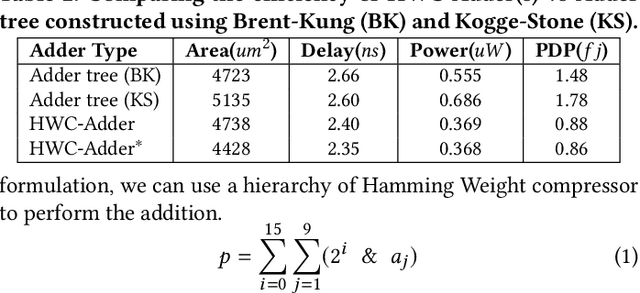
In this paper, we present NESTA, a specialized Neural engine that significantly accelerates the computation of convolution layers in a deep convolutional neural network, while reducing the computational energy. NESTA reformats Convolutions into $3 \times 3$ batches and uses a hierarchy of Hamming Weight Compressors to process each batch. Besides, when processing the convolution across multiple channels, NESTA, rather than computing the precise result of a convolution per channel, quickly computes an approximation of its partial sum, and a residual value such that if added to the approximate partial sum, generates the accurate output. Then, instead of immediately adding the residual, it uses (consumes) the residual when processing the next batch in the hamming weight compressors with available capacity. This mechanism shortens the critical path by avoiding the need to propagate carry signals during each round of computation and speeds up the convolution of each channel. In the last stage of computation, when the partial sum of the last channel is computed, NESTA terminates by adding the residual bits to the approximate output to generate a correct result.