 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Non-IID Data Quagmire of Decentralized Machine Learning
Paper and Code
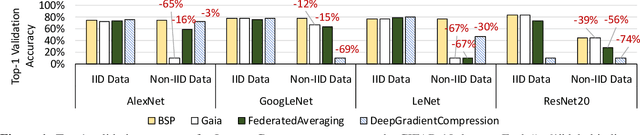
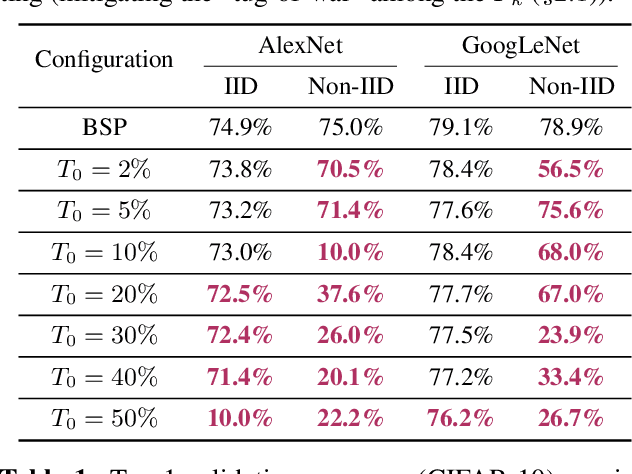
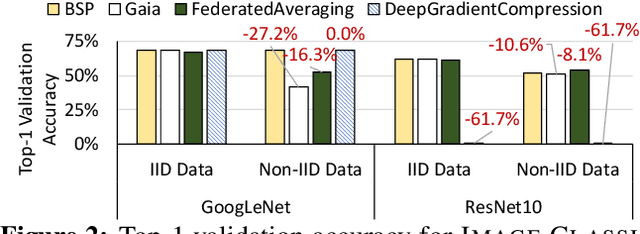

Many large-scale machine learning (ML) applications need to train ML models over decentralized datasets that are generated at different devices and locations. These decentralized datasets pose a fundamental challenge to ML because they are typically generated in very different contexts, which leads to significant differences in data distribution across devices/locations (i.e., they are not independent and identically distributed (IID)). In this work, we take a step toward better understanding this challenge, by presenting the first detailed experimental study of the impact of such non-IID data on the decentralized training of deep neural networks (DNNs). Our study shows that: (i) the problem of non-IID data partitions is fundamental and pervasive, as it exists in all ML applications, DNN models, training datasets, and decentralized learning algorithms in our study; (ii) this problem is particularly difficult for DNN models with batch normalization layers; and (iii) the degree of deviation from IID (the skewness) is a key determinant of the difficulty level of the problem. With these findings in mind, we present SkewScout, a system-level approach that adapts the communication frequency of decentralized learning algorithms to the (skew-induced) accuracy loss between data partitions. We also show that group normalization can recover much of the skew-induced accuracy loss of batch normalization.