 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatically Learning Data Augmentation Policies for Dialogue Tasks
Paper and Code
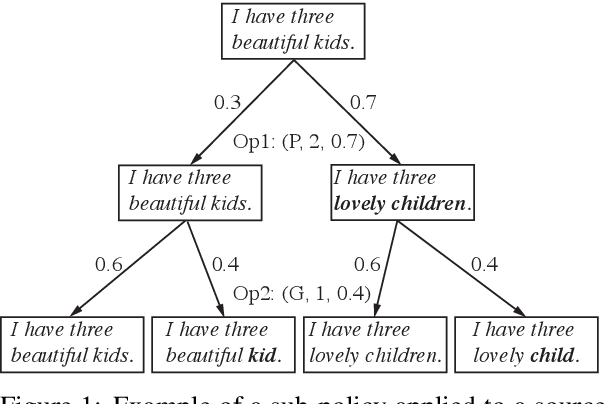
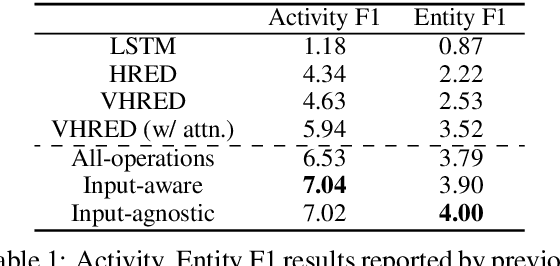
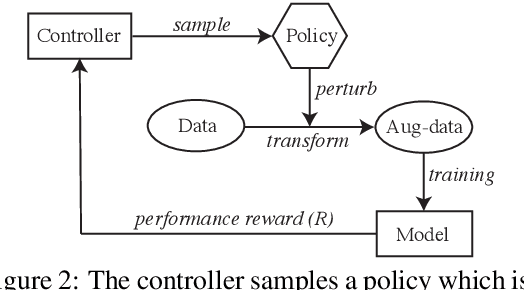
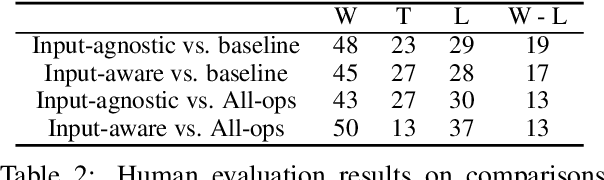
Automatic data augmentation (AutoAugment) (Cubuk et al., 2019) searches for optimal perturbation policies via a controller trained using performance rewards of a sampled policy on the target task, hence reducing data-level model bias. While being a powerful algorithm, their work has focused on computer vision tasks, where it is comparatively easy to apply imperceptible perturbations without changing an image's semantic meaning. In our work, we adapt AutoAugment to automatically discover effective perturbation policies for natural language processing (NLP) tasks such as dialogue generation. We start with a pool of atomic operations that apply subtle semantic-preserving perturbations to the source inputs of a dialogue task (e.g., different POS-tag types of stopword dropout, grammatical errors, and paraphrasing). Next, we allow the controller to learn more complex augmentation policies by searching over the space of the various combinations of these atomic operations. Moreover, we also explore conditioning the controller on the source inputs of the target task, since certain strategies may not apply to inputs that do not contain that strategy's required linguistic features. Empirically, we demonstrate that both our input-agnostic and input-aware controllers discover useful data augmentation policies, and achieve significant improvements over the previous state-of-the-art, including trained on manually-designed policies.