 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Massively Pretrained Language Models Make Better Storytellers?
Paper and Code
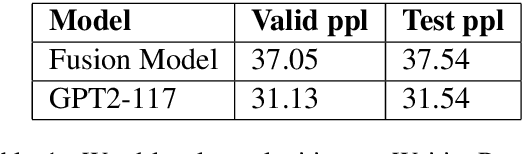
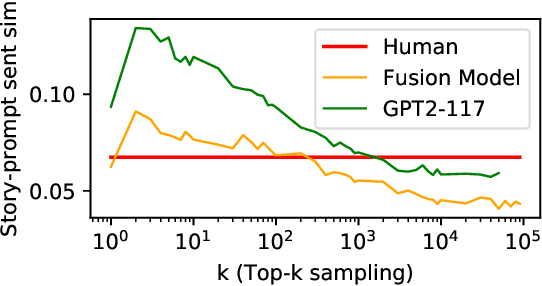
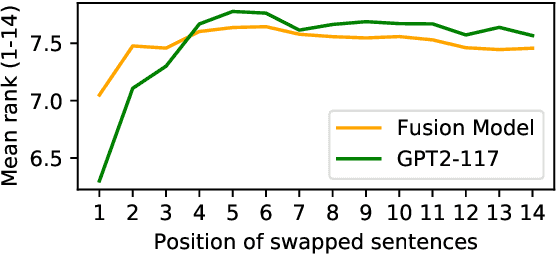

Large neural language models trained on massive amounts of text have emerged as a formidable strategy for Natural Language Understanding tasks. However, the strength of these models as Natural Language Generators is less clear. Though anecdotal evidence suggests that these models generate better quality text, there has been no detailed study characterizing their generation abilities. In this work, we compare the performance of an extensively pretrained model, OpenAI GPT2-117 (Radford et al., 2019), to a state-of-the-art neural story generation model (Fan et al., 2018). By evaluating the generated text across a wide variety of automatic metrics, we characterize the ways in which pretrained models do, and do not, make better storytellers. We find that although GPT2-117 conditions more strongly on context, is more sensitive to ordering of events, and uses more unusual words, it is just as likely to produce repetitive and under-diverse text when using likelihood-maximizing decoding algorithms.