 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCNN-based RGB-D Salient Object Detection: Learn, Select and Fuse
Paper and Code
Sep 20, 2019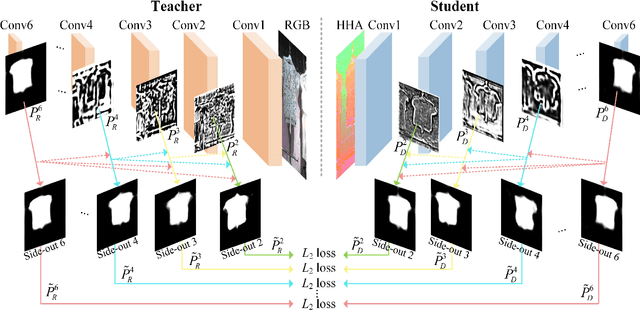

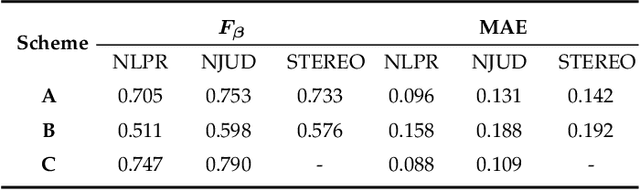
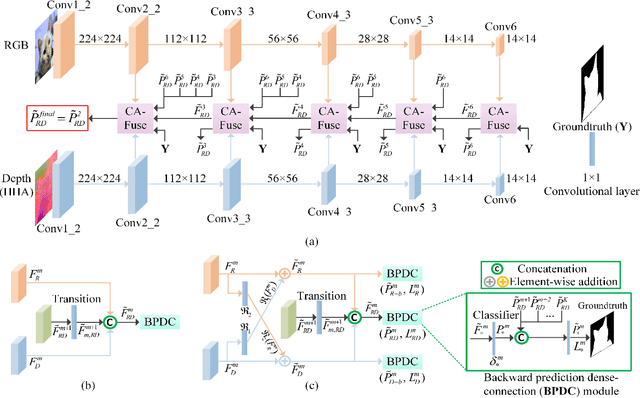
The goal of this work is to present a systematic solution for RGB-D salient object detection, which addresses the following three aspects with a unified framework: modal-specific representation learning, complementary cue selection and cross-modal complement fusion. To learn discriminative modal-specific features, we propose a hierarchical cross-modal distillation scheme, in which the well-learned source modality provides supervisory signals to facilitate the learning process for the new modality. To better extract the complementary cues, we formulate a residual function to incorporate complements from the paired modality adaptively. Furthermore, a top-down fusion structure is constructed for sufficient cross-modal interactions and cross-level transmissions. The experimental results demonstrate the effectiveness of the proposed cross-modal distillation scheme in zero-shot saliency detection and pre-training on a new modality, as well as the advantages in selecting and fusing cross-modal/cross-level complements.