 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlleviating Sequence Information Loss with Data Overlapping and Prime Batch Sizes
Paper and Code
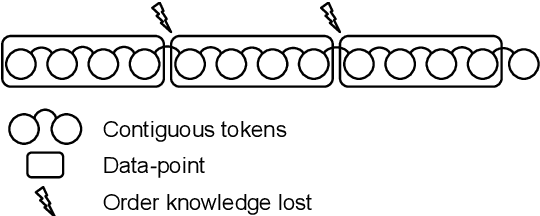

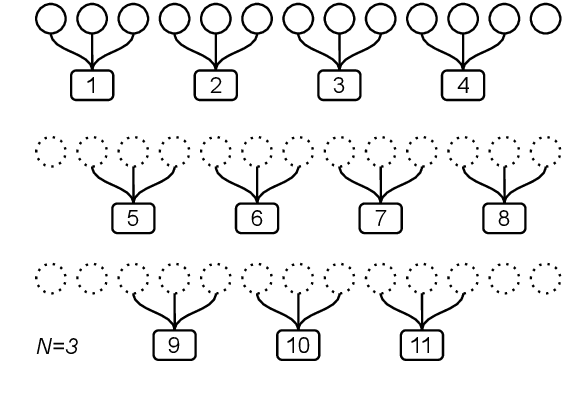
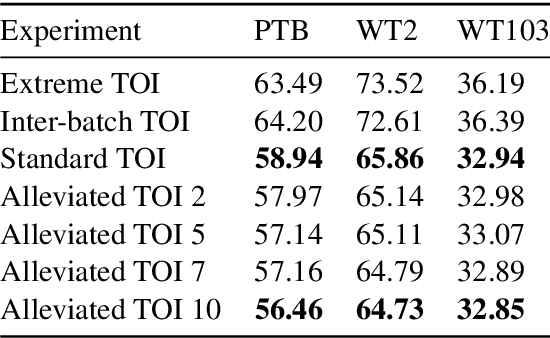
In sequence modeling tasks the token order matters, but this information can be partially lost due to the discretization of the sequence into data points. In this paper, we study the imbalance between the way certain token pairs are included in data points and others are not. We denote this a token order imbalance (TOI) and we link the partial sequence information loss to a diminished performance of the system as a whole, both in text and speech processing tasks. We then provide a mechanism to leverage the full token order information -Alleviated TOI- by iteratively overlapping the token composition of data points. For recurrent networks, we use prime numbers for the batch size to avoid redundancies when building batches from overlapped data points. The proposed method achieved state of the art performance in both text and speech related tasks.