 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimple, Scalable Adaptation for Neural Machine Translation
Paper and Code
Sep 18, 2019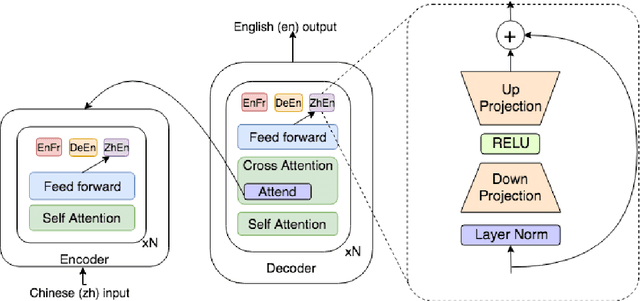
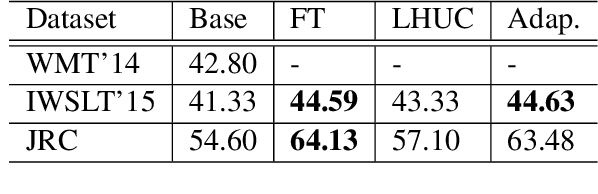
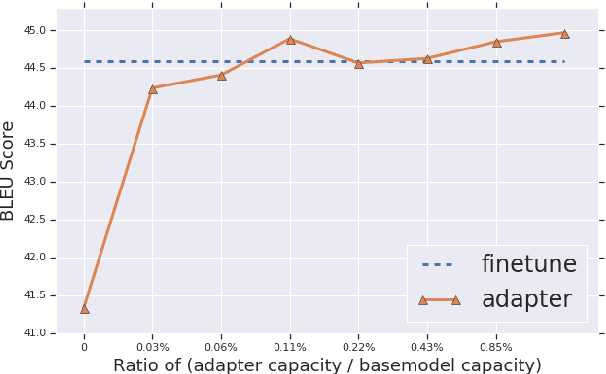
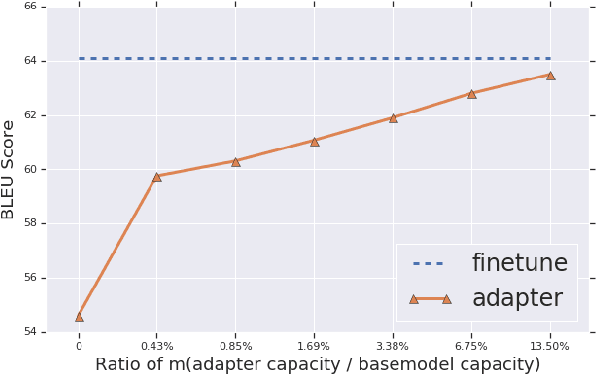
Fine-tuning pre-trained Neural Machine Translation (NMT) models is the dominant approach for adapting to new languages and domains. However, fine-tuning requires adapting and maintaining a separate model for each target task. We propose a simple yet efficient approach for adaptation in NMT. Our proposed approach consists of injecting tiny task specific adapter layers into a pre-trained model. These lightweight adapters, with just a small fraction of the original model size, adapt the model to multiple individual tasks simultaneously. We evaluate our approach on two tasks: (i) Domain Adaptation and (ii) Massively Multilingual NMT. Experiments on domain adaptation demonstrate that our proposed approach is on par with full fine-tuning on various domains, dataset sizes and model capacities. On a massively multilingual dataset of 103 languages, our adaptation approach bridges the gap between individual bilingual models and one massively multilingual model for most language pairs, paving the way towards universal machine translation.