 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Separability of Classes with the Cross-Entropy Loss Function
Paper and Code
Sep 16, 2019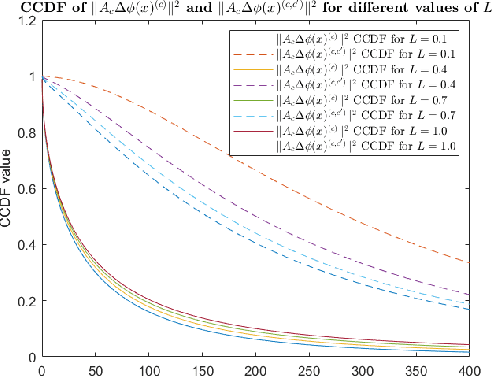
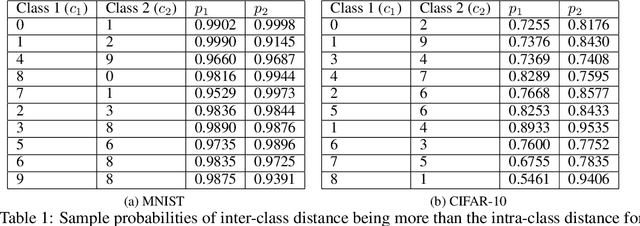
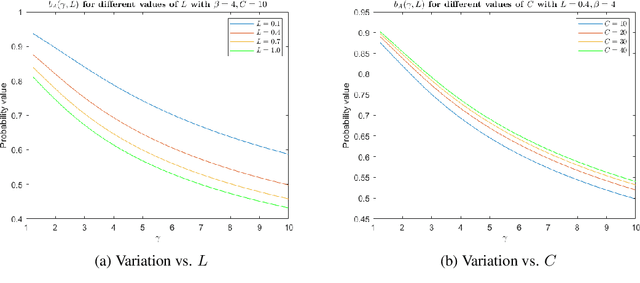
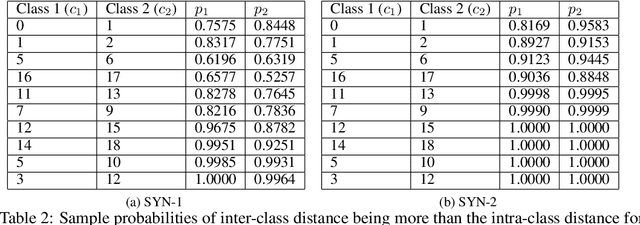
In this paper, we focus on the separability of classes with the cross-entropy loss function for classification problems by theoretically analyzing the intra-class distance and inter-class distance (i.e. the distance between any two points belonging to the same class and different classes, respectively) in the feature space, i.e. the space of representations learnt by neural networks. Specifically, we consider an arbitrary network architecture having a fully connected final layer with Softmax activation and trained using the cross-entropy loss. We derive expressions for the value and the distribution of the squared L2 norm of the product of a network dependent matrix and a random intra-class and inter-class distance vector (i.e. the vector between any two points belonging to the same class and different classes), respectively, in the learnt feature space (or the transformation of the original data) just before Softmax activation, as a function of the cross-entropy loss value. The main result of our analysis is the derivation of a lower bound for the probability with which the inter-class distance is more than the intra-class distance in this feature space, as a function of the loss value. We do so by leveraging some empirical statistical observations with mild assumptions and sound theoretical analysis. As per intuition, the probability with which the inter-class distance is more than the intra-class distance decreases as the loss value increases, i.e. the classes are better separated when the loss value is low. To the best of our knowledge, this is the first work of theoretical nature trying to explain the separability of classes in the feature space learnt by neural networks trained with the cross-entropy loss function.