 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnaligned Sequence Similarity Search Using Deep Learning
Paper and Code
Sep 16, 2019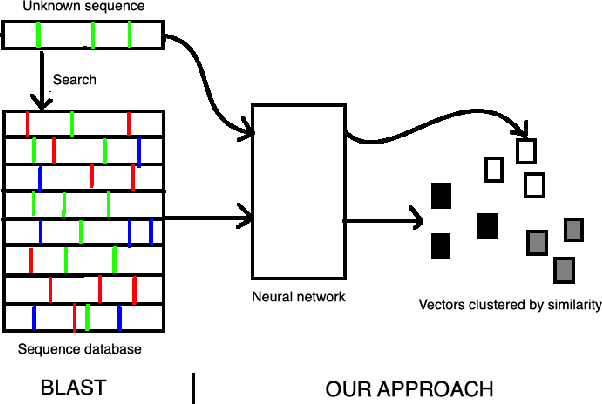
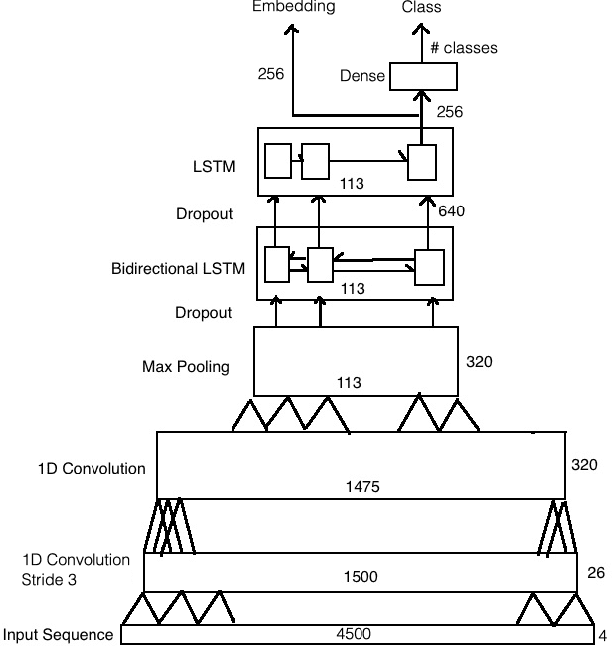
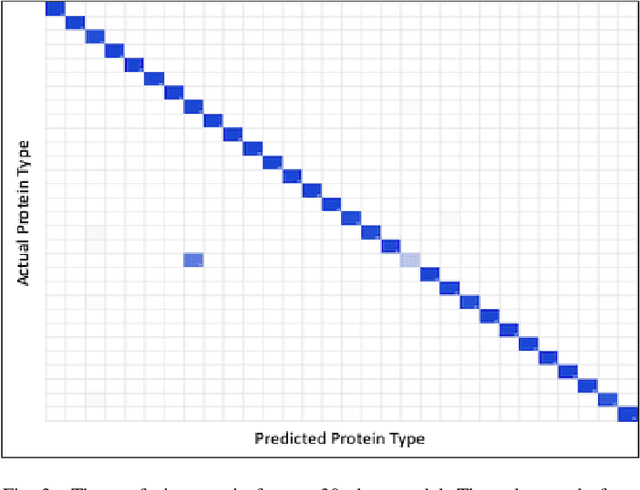

Gene annotation has traditionally required direct comparison of DNA sequences between an unknown gene and a database of known ones using string comparison methods. However, these methods do not provide useful information when a gene does not have a close match in the database. In addition, each comparison can be costly when the database is large since it requires alignments and a series of string comparisons. In this work we propose a novel approach: using recurrent neural networks to embed DNA or amino-acid sequences in a low-dimensional space in which distances correlate with functional similarity. This embedding space overcomes both shortcomings of the method of aligning sequences and comparing homology. First, it allows us to obtain information about genes which do not have exact matches by measuring their similarity to other ones in the database. If our database is labeled this can provide labels for a query gene as is done in traditional methods. However, even if the database is unlabeled it allows us to find clusters and infer some characteristics of the gene population. In addition, each comparison is much faster than traditional methods since the distance metric is reduced to the Euclidean distance, and thus efficient approximate nearest neighbor algorithms can be used to find the best match. We present results showing the advantage of our algorithm. More specifically we show how our embedding can be useful for both classification tasks when our labels are known, and clustering tasks where our sequences belong to classes which have not been seen before.