 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCountering the Effects of Lead Bias in News Summarization via Multi-Stage Training and Auxiliary Losses
Paper and Code
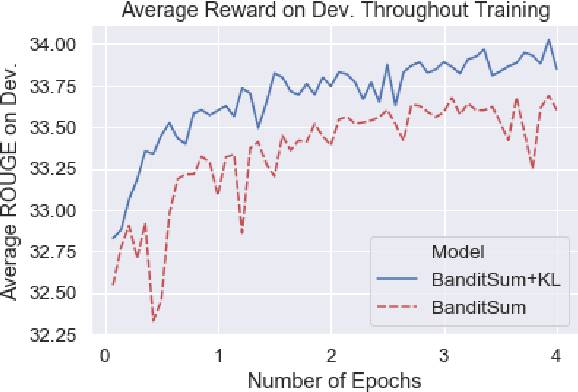
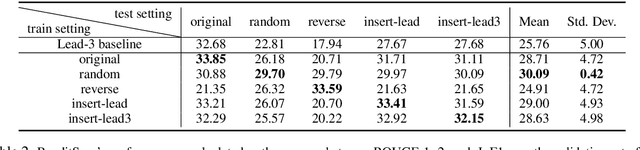
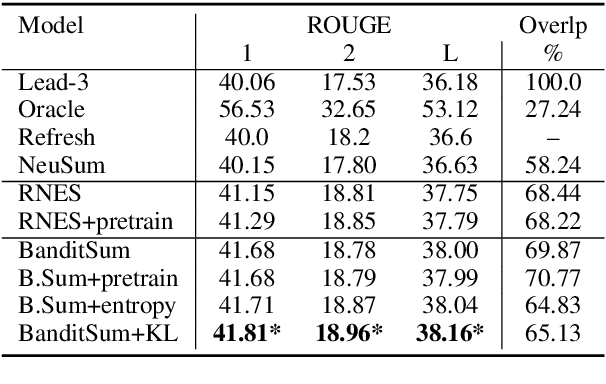
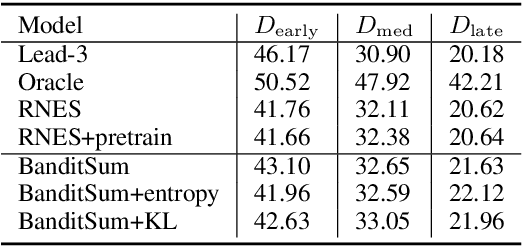
Sentence position is a strong feature for news summarization, since the lead often (but not always) summarizes the key points of the article. In this paper, we show that recent neural systems excessively exploit this trend, which although powerful for many inputs, is also detrimental when summarizing documents where important content should be extracted from later parts of the article. We propose two techniques to make systems sensitive to the importance of content in different parts of the article. The first technique employs 'unbiased' data; i.e., randomly shuffled sentences of the source document, to pretrain the model. The second technique uses an auxiliary ROUGE-based loss that encourages the model to distribute importance scores throughout a document by mimicking sentence-level ROUGE scores on the training data. We show that these techniques significantly improve the performance of a competitive reinforcement learning based extractive system, with the auxiliary loss being more powerful than pretraining.