 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscriminative Video Representation Learning Using Support Vector Classifiers
Paper and Code
Sep 05, 2019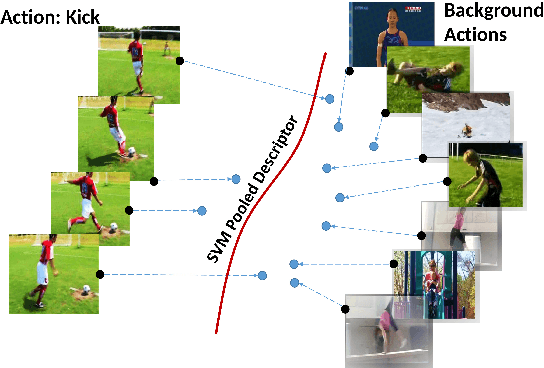

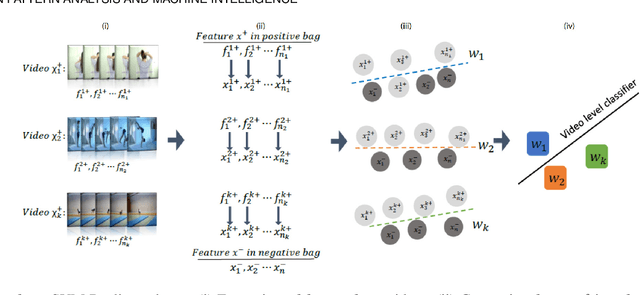
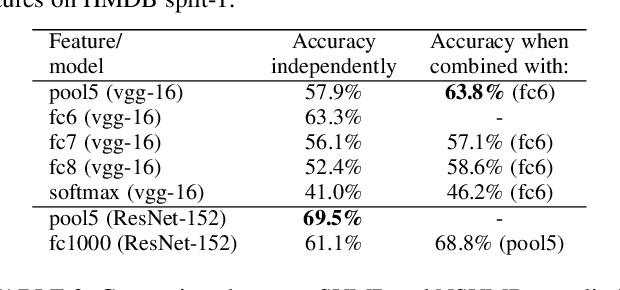
Most popular deep models for action recognition in videos generate independent predictions for short clips, which are then pooled heuristically to assign an action label to the full video segment. As not all frames may characterize the underlying action---many are common across multiple actions---pooling schemes that impose equal importance on all frames might be unfavorable. In an attempt to tackle this problem, we propose discriminative pooling, based on the notion that among the deep features generated on all short clips, there is at least one that characterizes the action. To identify these useful features, we resort to a negative bag consisting of features that are known to be irrelevant, for example, they are sampled either from datasets that are unrelated to our actions of interest or are CNN features produced via random noise as input. With the features from the video as a positive bag and the irrelevant features as the negative bag, we cast an objective to learn a (nonlinear) hyperplane that separates the unknown useful features from the rest in a multiple instance learning formulation within a support vector machine setup. We use the parameters of this separating hyperplane as a descriptor for the full video segment. Since these parameters are directly related to the support vectors in a max-margin framework, they can be treated as a weighted average pooling of the features from the bags, with zero weights given to non-support vectors. Our pooling scheme is end-to-end trainable within a deep learning framework. We report results from experiments on eight computer vision benchmark datasets spanning a variety of video-related tasks and demonstrate state-of-the-art performance across these tasks.