 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpirical Analysis of Knowledge Distillation Technique for Optimization of Quantized Deep Neural Networks
Paper and Code
Oct 05, 2019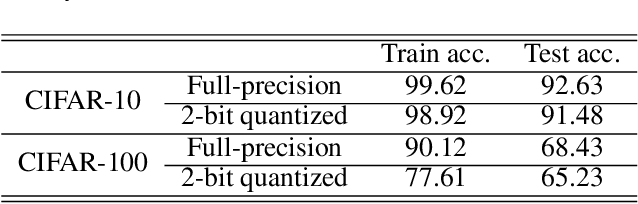
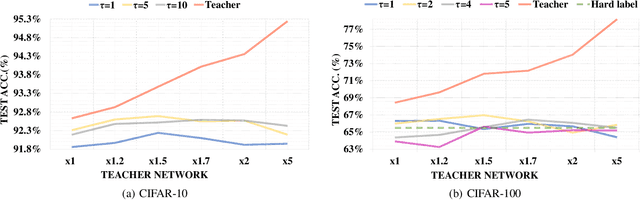
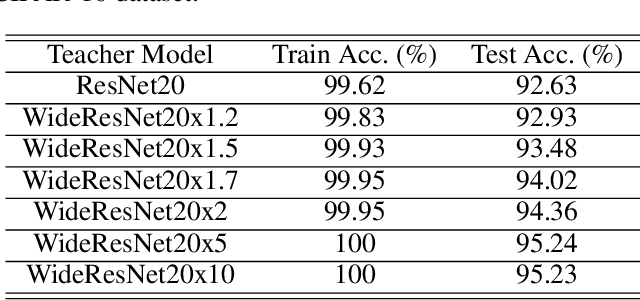
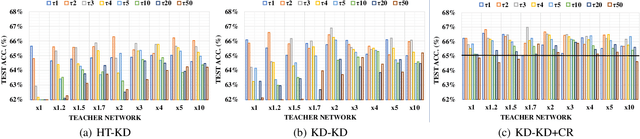
Knowledge distillation (KD) is a very popular method for model size reduction. Recently, the technique is exploited for quantized deep neural networks (QDNNs) training as a way to restore the performance sacrificed by word-length reduction. KD, however, employs additional hyper-parameters, such as temperature, coefficient, and the size of teacher network for QDNN training. We analyze the effect of these hyper-parameters for QDNN optimization with KD. We find that these hyper-parameters are inter-related, and also introduce a simple and effective technique that reduces \textit{coefficient} during training. With KD employing the proposed hyper-parameters, we achieve the test accuracy of 92.7% and 67.0% on Resnet20 with 2-bit ternary weights for CIFAR-10 and CIFAR-100 data sets, respectively.