 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Bootstrapping for Dialogue Model Training
Paper and Code
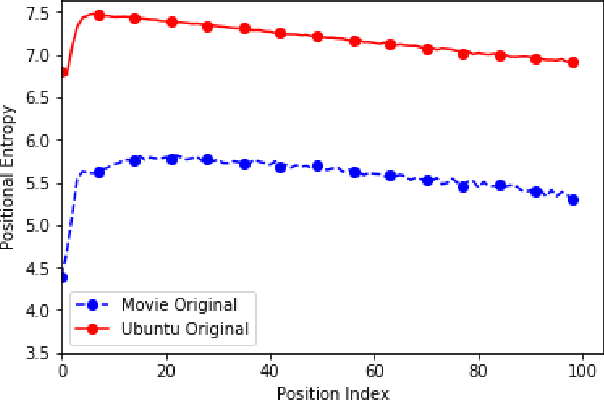
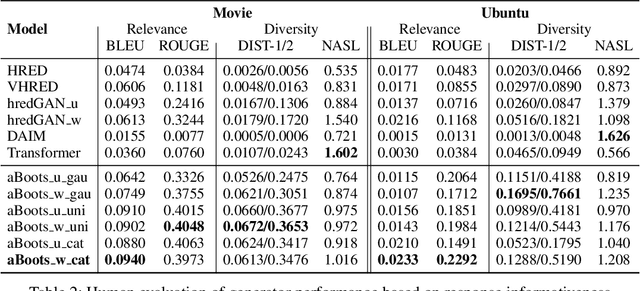
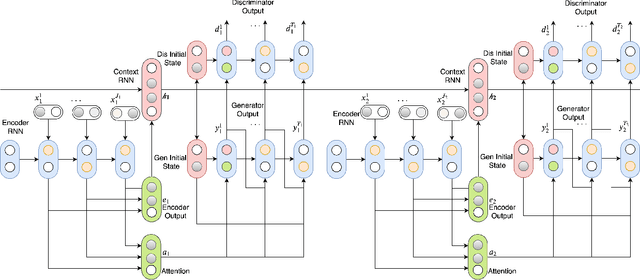
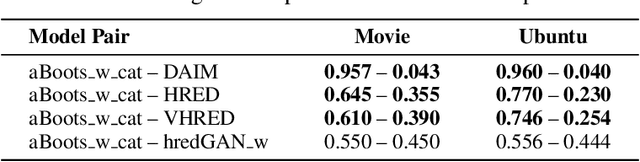
Open domain neural dialogue models, despite their successes, are known to produce responses that lack relevance, diversity, and in many cases coherence. These shortcomings stem from the limited ability of common training objectives to directly express these properties as well as their interplay with training datasets and model architectures. Toward addressing these problems, this paper proposes bootstrapping a dialogue response generator with an adversarially trained discriminator. The method involves training a neural generator in both autoregressive and traditional teacher-forcing modes, with the maximum likelihood loss of the auto-regressive outputs weighted by the score from a metric-based discriminator model. The discriminator input is a mixture of ground truth labels, the teacher-forcing outputs of the generator, and distractors sampled from the dataset, thereby allowing for richer feedback on the autoregressive outputs of the generator. To improve the calibration of the discriminator output, we also bootstrap the discriminator with the matching of the intermediate features of the ground truth and the generator's autoregressive output. We explore different sampling and adversarial policy optimization strategies during training in order to understand how to encourage response diversity without sacrificing relevance. Our experiments shows that adversarial bootstrapping is effective at addressing exposure bias, leading to improvement in response relevance and coherence. The improvement is demonstrated with the state-of-the-art results on the Movie and Ubuntu dialogue datasets with respect to human evaluations and BLUE, ROGUE, and distinct n-gram scores.